
The Generative AI Canon
A learning roadmap for genAI, from concepts to calculus

This article is for people how want to level-up knowledge about state-of-the-art products and research in the field of Generative AI (genAI). Whether you’re just starting to learn about this transformative field—or you’re ready to learn the science and math behind it—this is for you.
Updated April 19, 2023: added new sections for Generative Agents; Vector Embeddings & Databases; updated to the 2023 version of the Stanford AI report; added some new content pertaining to virtual beings, language-models within games, and shader programming with ChatGPT.

Unlike other collections, the Generative AI Canon has two important goals:
High curation—not a random collection of everything.
Accessible yet deep—includes suggestions on gaining knowledge for newcomers, all the way to the math & theory for anyone who wishes to plumb the depths.
I’ve organized this as a set of lenses that let you peer into the important subdomains of genAI to learn about the applications and cutting-edge research.
Each section is also a roadmap, roughly organized from exemplars and the more conceptual, then advancing towards the more technical and foundational.
This roadmap structure also flows around the overall organization of the article: beginning with the most conceptual, before extending to the more challenging topics.
The Lenses:
Vision: what’s the big picture for what genAI means to the world?
Business Topics: market trends, measurements, financial impact.
Games and Virtual World Development: my own area of specialization, outlining the technologies that will lead to the “Direct from Imagination” era.
2D Images: genAI used to create artwork and “photos.”
3D Pipelines: addresses all the genAI being used within the complex set of steps involved in 3D scenes, models, texture maps, rigging and animation.
Natural Language Processing: about large language models, how to understand them, and ChatGPT.
Video: the latest advances and foundational research relating to video composition and editing.
Audio & Music: generative voice-over, music and sound effects.
Culture, Ethics & Legal: some of the current issues pertaining to society.
Deepfakes and Authenticity: creating content that looks like it came from a specific person.
Digital to Physical: how generative AI will begin to reshape our physical reality.
Scale and Performance: how hardware and model size has led to the breakthroughs in generative AI.
Road to AGI: how generative technologies may lead to Artificial General Intelligence.
Deep Learning & Transformers: the foundational research and technology that has led to most generative breakthroughs.
Theory & Mathematics: for when you want to go deep, and what to learn if you want to start understanding the more technical papers.
Memes: probably nothing.
Vision
Software 2.0 by Andrej Karpathy explains why and how “AI is eating software, the way software is eating the world.
The Direct from Imagination Era has Begun is my article on what life looks like—and how we get there—when you can “speak entire universes into existence.”
Generative AI: the Anything from Anything Machine by Strange Loop Canon
Interview with Emad Mostaque (CEO of Stable Diffusion) about the role of AI in creative fields:
Business Topics
Secret Cyborgs: The Present Disruption in Three Papers provides a summary of why generative AI (specifically, language models) may already be adding more productivity than steam power.

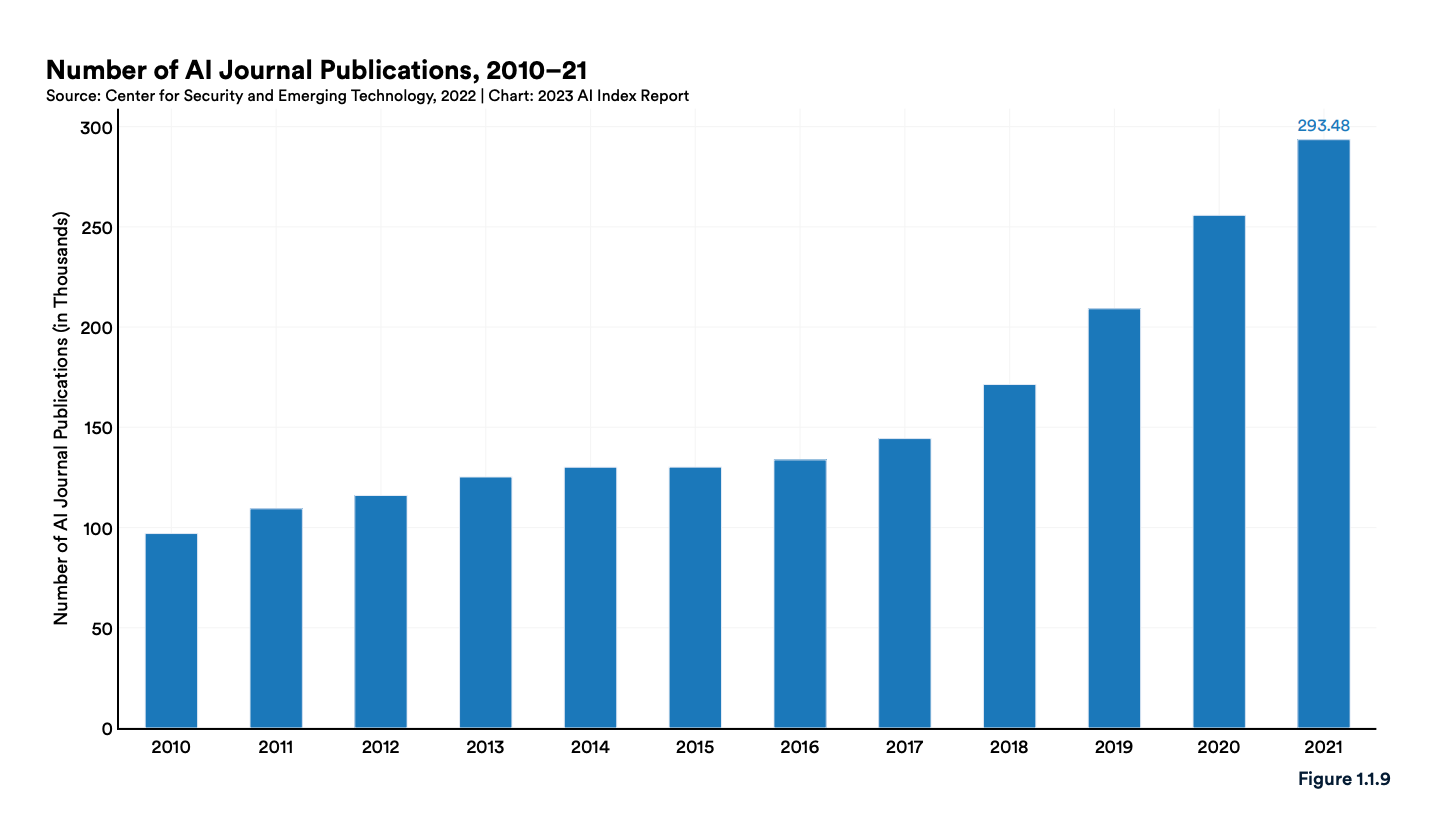
The 2023 Artificial Intelligence Index Report from Stanford is a wonderful compilation of data illustrating trends in research, R&D spending, the technical performance of various AI models.
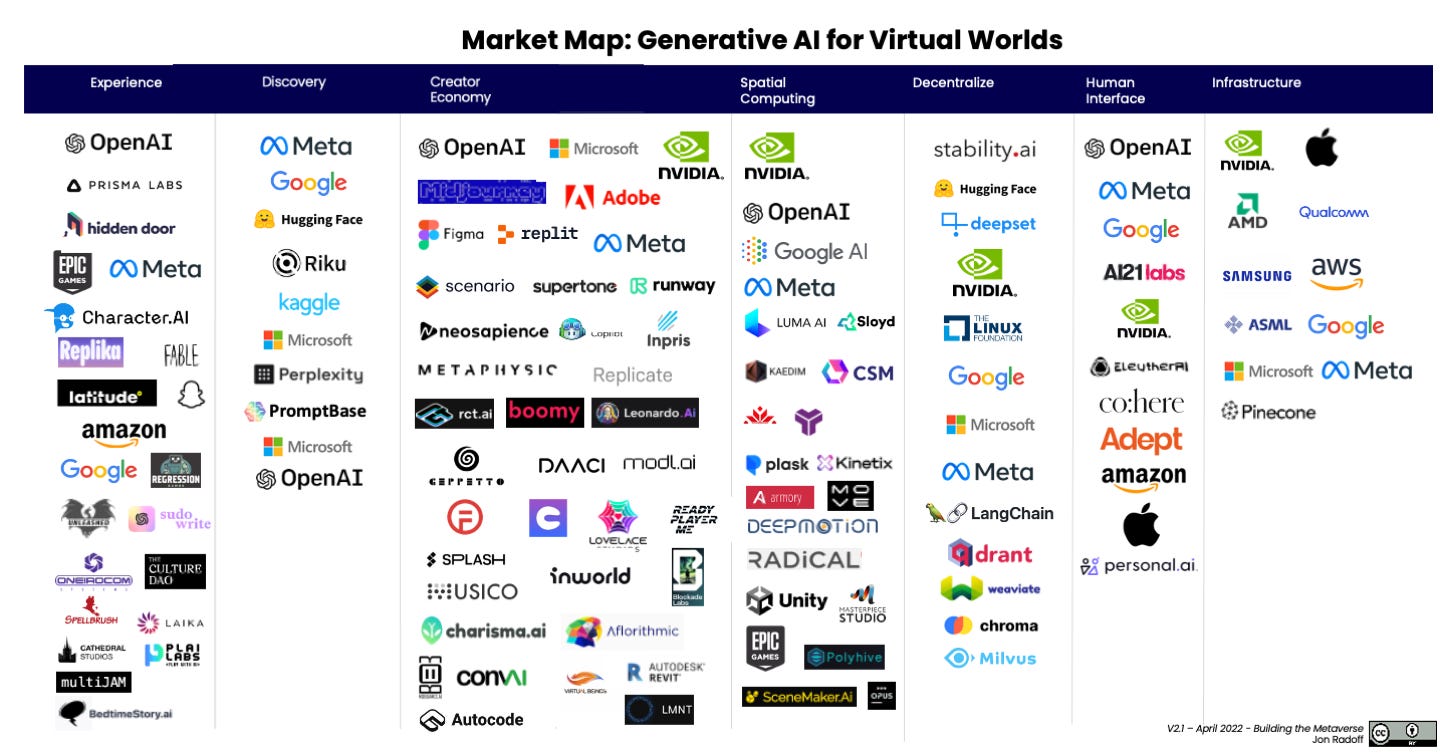
Market Map: Generative AI for Virtual Worlds is my description of the market, organized by the value-chain: from the semiconductors enabling it, on up to the experiences enabled by genAI.
Takeaways from 3 Years Working in Machine Learning Episteminkis not specifically about genAI, but offers some pragmatic advice that applies here: the most interesting business opportunities will revolve around understanding the trajectory of hardware, and identifying paradigm shifts in the nature of work.
AI and the Big Five (Stratechery) is about the impact of AI on Apple, Amazon, Meta, Google and Microsoft—both the opportunities, and the role of the innovator’s dilemma.
Abandoning intuition: using Generative AI for advertising creative by Eric Seufert makes the case for why genAI applied to marketing may be one of the most actionable areas of development in the field.
This epic Twitter thread about AI by Jack Soslow from a16z is a great summary of many of the important trends and papers.
Game and Virtual World Development
Games and virtual worlds are my own area of expertise—one I share with some of the leaders in artificial intelligence: Demis Hassabis was a chess champion and game developer before becoming CEO of DeepMind. Many others have cited the influence of playing board games and video games on their road to investigating artificial intelligence.
I’ve made a couple simple proof-of-concepts using ChatGPT. One is a classic-style text adventure game demo.
Five Levels of Generative AI for Games is my article, using the structure originally devised for tracking progress in autonomous vehicles, and applying it across the different class of creators involved in game development.

Here are some papers and projects that reflect progress towards the higher levels (3-5) of GenAI in game development:
GANTheftAuto is a fork of the GameGAN model that shows how a generative adversarial model can be used to learn to play a game (Grand Theft Auto) and then generate an experience similar to the game itself.
Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos is. a paper which explains how OpenAI researchers taught an AI to play Minecraft by observing YouTube videos of people playing it (here’s a less technical explanation).
CICERO AI plays Diplomacy. This research at Meta illustrates how an AI can used a combination of historical gameplay as well as language models to participate in complex negotiations and tactics with human players.
The DeepNash model beat humans at Stratego—like poker and Diplomacy, a game of incomplete information.
Level Generation Through Large Language Models shows the how a language model may be used to do some of the same types of level-generation that has been done in the past in roguelike games (Procedural Content Generation) — but in a more generalized fashion.
MarioGPT: Open-Ended Text2Level Generation through Large Language Models demonstrates a fine-tuned GPT2 model that creates Super Mario levels.
Libratus: the Superhuman AI for No-Limit Poker is the first artificial intelligence that learned to beat top human poker players.

Old Atari 2600 games have become a means of designing and building a number of AI systems; the DreamerV2 agent in TensorFlow 2 shows how an AI can learn to generate strategies with superhuman performance in these games.
Game development usually involves many other forms of media (art, music, etc.) and those will be covered below.
2D Images
The main software people currently use to make 2D art includes Midjourney and Stable Diffusion, which are based on diffusion models. Software that is focused on the use of these models to create 2D game assets include Scenario.gg and Leonardo.ai.
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion shows how a set of sample images can be morphed into new forms (e.g., an input sculpture into an output of a painting or an Elmo doll).

Diffusion Models Beat GANs on Image Synthesis is the paper that shows why and how the current image generators like Midjourney and Stable Diffusion use Diffusion Models (which start from noise, and progressively sharpen to an image), which has replaced the generative adversarial networks (GANs) that were popular until then. (Yannic Kilcher has an excellent video walkthrough of the paper).
Adding Conditional Control to Text-to-Image Diffusion Models is a paper that introduced the science behind ControlNet, which enables posing of characters within diffusion-based 2D image generation.
Deep Unsupervised Learning using Nonequilibrium Dynamics is a technical paper on the origins of the diffusion algorithm now in use for most of the popular image generators.
Generative Adversarial Text to Image Synthesis described earlier text-to-image techniques using Generative Adversarial Networks (GANs).
Much of the ability to generate images from a text prompt from earlier work to generate image captions, described in Show and Tell: a Neural Image Caption Generator (Google).
3D Pipelines

As you can see from my diagram above, art pipelines for 3D graphics are far more complex than 2D graphics. Each step has particular problems that can be solved by generative AI. I’ll highlight each of the above:
2D-to-3D: Jussi Kemppainen shows how he starts in Midjourney, and then uses a pipeline with fSpy, Blender and Unity to create a playable 3D world (a more expansive write-up on AI Assisted Game Development may be found here).
 Jussi Kemppainen@JussiKemppainenAI Assisted experimental game scene breakdown. From @midjourney to @unity trough fSpy & @Blender. Devblog: echoesofsomewhere.com/2023/02/11/ai-… #indiedev #madewithunity #Blender3d3:49 PM · Feb 15, 2023149 Reposts · 822 Likes
Jussi Kemppainen@JussiKemppainenAI Assisted experimental game scene breakdown. From @midjourney to @unity trough fSpy & @Blender. Devblog: echoesofsomewhere.com/2023/02/11/ai-… #indiedev #madewithunity #Blender3d3:49 PM · Feb 15, 2023149 Reposts · 822 LikesText-to-3D: Magic3D: High-Resolution Text-to-3D Content Creation is a paper explaining how text prompts can be used to make a 3D model. Commericial projects doing text-to-3D include Masterpiece Studio; and Scenario.gg is working towards it.
3D-aware Conditional Image Synthesis: this paper shows how you can take a 2D label map and converts it into a 3D model; an application of this is to treat a sketch as an edge-map that turns it into a model (“sketch-to-3D.”)
UV Unwrap: The process of unwrapping a UV (i.e., taking the texture map on a 3D model and turning into a paintable surface) is one of the most unliked jobs in the process of building 3D art, and seems to be an area ripe for automation using AI. StyleUV: Diverse and High-fidelity UV Map Generative Model is a paper about a model to solve for that problem; and MvDeCor: Multi-view Dense Correspondence Learning for Fine-grained 3D Segmentation shows how an AI may be trained to identify specific regions (e.g., parts of a face) that ought to apply to the same problem.
Rigging and Animation: Morig: Motion-Aware Rigging of Character Meshes from Point Clouds is an AI to generate rigged and animated models. Commercial products like DeepMotion Masterpiece Studio, and Kinetix are focused on these problems (some using text-prompting, others using video inputs).
Collision Detection: one of the hard problems with 3D scenes is that complex geometries can be difficult to perform accurate collision detection on (e.g., seeing if a projectile strikes a target). Deep learning can be applied to signed distance functions to optimize these algorithms (among other applications).
Video-to-3D: BANMo: Building Animatable 3D Neural Models from Many Casual Videos demonstrates how 3D models can be animated based on the ingesting videos.
Text-to-3D-Animation: PADL: Language-Directed Physics-Based Character Control shows how animated models can interact with 3D environments, with appropriate physics, based on instructions from a text prompt.
Text-to-World: SceneScape: Text-Driven Consistent Scene Generation shows how you could create scenes that look similar to each other from a text prompt. Seems like a great way to build an endless runner game!
Audio-to-Animation: Omniverse Audio2Face shows how you could use speech input to create animated faces along with basic emotional inputs.
Neural Radiance Fields (NeRFs)
NeRFs are a method for generating 3D scenes from a sparse set of 2D inputs, such as photos taken of an area. They may be used to generate both 2D images that are “3D-ish” (i.e., they look as if rendered from a 3D engine) or they could involve actual polygonal geometry. The approach is essentially the inverse of ray tracing. There are a wide range of generative applications, including capturing objects from reality and bringing them into 3D engines—perhaps as an alternative or successor to approaches like photogrammetry.
A short 170 year history of Neural Radiance Fields (NeRF), Holograms, and Light Fields is a gentle introduction to NeRF technology, going back to 1850’s photo sculpture, the 1908 discovery of the plenoptic function, and how this led to reverse raytracing techniques.
Representing Scenes as Neural Radiance Fields for View Synthesis (NeRF) describes the inverse ray-tracing method.
Neural Fields in Visual Computing surveys many of the applications for NeRFs, including synthesizing views, animation of human forms, and robotics.
Natural Language Processing (NLP)
What is ChatGPT Doing and Why Does it Work by Stephen Wolfram is simply the best overall explanation of large language models (LLMs), starting from a gentle technical introduction for people who are comfortable with pseudocode—but goes deep into topics like network theory, complexity and computational limits. It also includes a good conceptual explanation of gradient descent (although oddly, he doesn’t call it by name).

Most people have tried ChatGPT at this point (it is one of the fastest growing applications in all of history). And people have discovered a number of interesting use cases:
ChatGPT received a passing grade on a law school exam.
ChatGPT received a passing grade on the US Medical Licensing exam.
ChatGPT passes a Wharton MBA exam.
ChatGPT-written abstracts for scientific papers fools scientists
Meta briefly shared Galactica, a generator for science papers, but took it offline after 3 days.
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing (Liu et al) is a report on the prompting methods used across natural language systems (GPT, etc.)

Hugging Face reports on the role of reinforcement learning from human feedback (RLHF), which was a significant contributor toward’s the perceived quality of ChatGPT’s results.
Improving Language Understanding by Generative Pre-Training is the paper that introduced GPT, the transformer-based architecture for ChatGPT that has—ahem—transformed the world of natural language processing.
Recipes for building an open domain chatbot describes the use of personas that are intended to allow chat systems to take on specific characters and roles that appear more human and engaging. This is an area of development at Character.ai and has applicability to virtual beings.
One of the applications of language models is to create characters or new experiences in online games. That was the subject of my conversation with Hilary Mason here:
Code and Symbolic Logic
At Beamable we also showed how you could use ChatGPT, Beamable and Unreal Blueprints to create the foundational code for an MMORPG, one of the most complex game categories that exist.

CommitGPT is an application that uses ChatGPT to automate the tedium of writing commit messages for GitHub.
Wolfram Alpha shows how data-aware modules will augment chat interfaces with rigorous data sources.
Perplexity.ai shows how you can build a natural-language layer around SQL queries that may be used to interact with database sources such as Twitter.

Chat2VIS shows how LLMs can be used to automate the creation of data visualizations. Connecting data sources together, arranging the intersections and surfacing it to attractive-looking charts will be something anyone can do.
Keijiro showed how language could be used to generate shaders, one of the more complex types of code written for 3D graphics systems (especially videogames):

Evaluating Large Language Models Trained on Code is that paper that introduced Codex, an OpenAI model fined-tuned from GPT for coding assistance. It is used to power applications like CoPilot.
Video
Make-A-Video: Text-to-Video Generation Without Text-Video Data shows how text prompts can generate new videos using a diffusion model (demonstration website with videos here).

Gen-1: The Next Step Forward for Generative AI shows how new videos can be generated from input videos and images.

Dreamix: Video Diffusion Models are General Video Editors shows how text-prompts can be used to create new animations and insert new content into exist videos.

NVIDIA’s deep learning super sampling (DLSS) technology is able to take lower-resolution input streams, and upgrade them to high-resolution outputs in real-time (e.g., for upgrading old games without needing new software to be written). The following is a video showing DLSS applied to Cyberpunk 2077:
Audio & Music
Commercial products to generate music are beginning to emerge, such as Musico. Generative voice over are available from companies like Aflorithmic and Elevenlabs.
Google created MusicML, a generative model that outputs melodies and music compositions based on text prompts, although they haven’t released the model. An interesting integration of multiple generative AIs: generating music to accompany auto-captioning of an image.
OpenAI demonstrated Jukebox, a generative music AI with the ability to co-create new music inspired by the likes of Elvis Presley and Katy Perry. Here’s an example:
How about sound design? Electronic Arts published Neural Synthesis of Sound Effects Using Flow-Based Deep Generative Models.
Much of the above research benefits from earlier work on WaveGAN, which was introduced in Adversarial Audio Synthesis.
Culture, Ethics & Legal
Copyright…for AI Graphic Novel is about what is believed to be the first copyright registration of an AI-assisted work, the Zarya of the Dawn comic book by Kris Kashtanova.
Concept Art Association’s advocacy page takes the position that AI text-to-image technology is unethical. They fund a lobbying effort in Washington DC to oppose generative artificial intelligence work; I don’t share many of their views, but think it’s important we hear from objectors and understand their concerns—whichever side you fall on.
Stable Diffusion Frivolous is a detailed breakdown of the technical and legal claims of the widely-publicized lawsuit against Stability AI, Midjourney and DeviantArt, written by “tech enthusiasts uninvolved in the case, and not lawyers, for the purpose of fighting misinformation.”
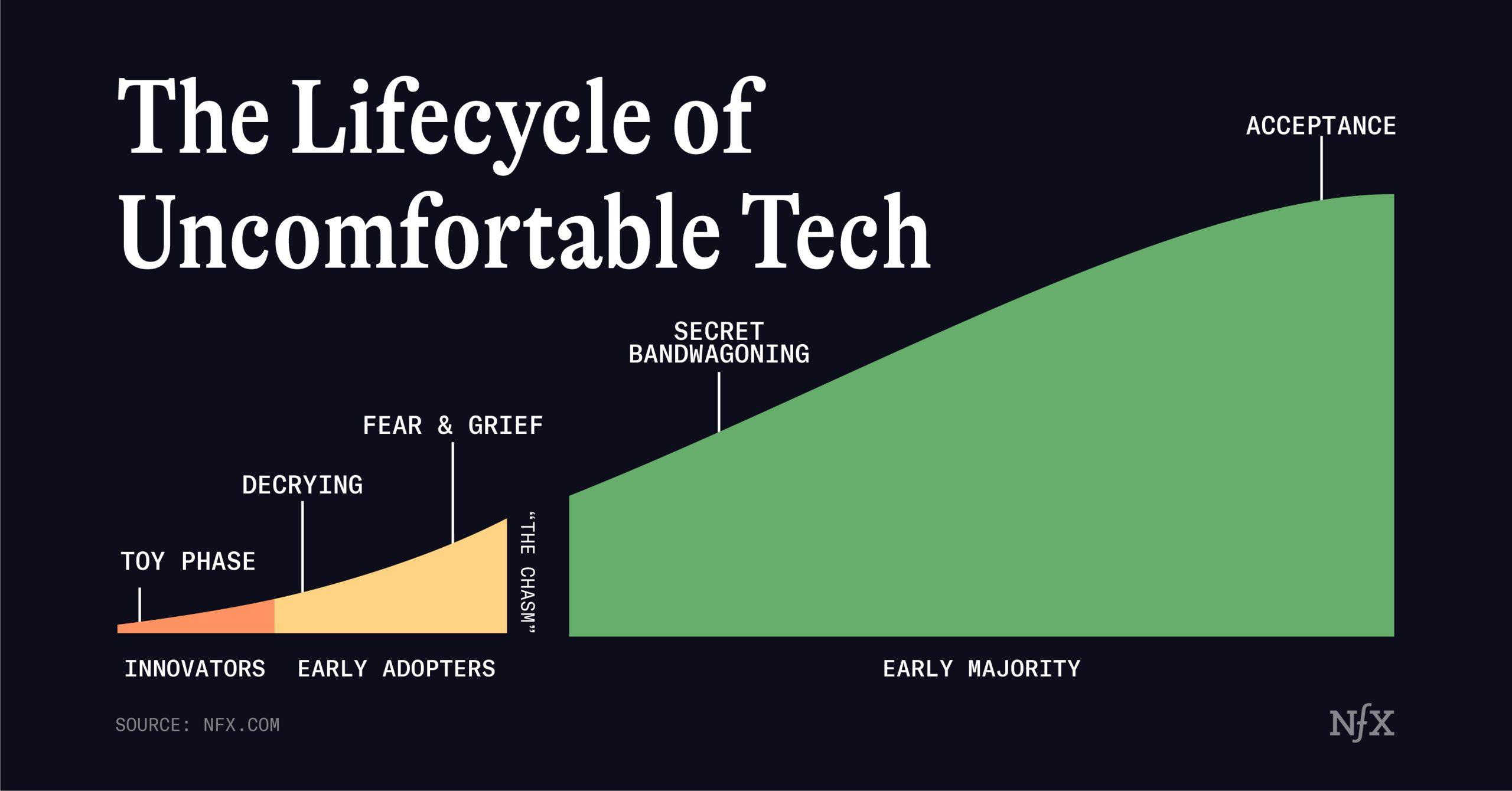
The Lifecycle of Uncomfortable Tech (James Currier) is about how—when a new technology disrupts existing work—that it tends to go through predictable phases, and different segments of society react in different ways according to their own incentives. Most generative AI today falls between the “toy” and “decrying” phases.
My article, The Work of Art in the Age of Generative AI, attempts to look at the world of generative imagery and makes the claim that most “art” is not actually art.
Introducing the AI Mirror Test (James Vincent) is about how generative text shows people a reflection of themselves (and society overall) and that smart people are failing to see themselves in the responses given.
Deepfakes and Authenticity
Deepfakes (Wikipedia) gives an overview of the use of generative AI to create videos, photos and audio of a well-known person. There are some legitimate purposes (art, parody, licensed uses) as well as the more nefarious (blackmail, porn, political manipulation).
The People Onscreen Are Fake. The Disinformation Is Real (New York Times) describes uses of deepfake and synthetic avatar technology to spread disinformation connected with pro-China actors.
Deepfake detection by human crowds, machines, and machine-informed crowds reports on an experiment conducted at the MIT Media Lab that found that humans and machines (using the best detection algorithms of 2021) do about as well as each other on deepfake detection; my take-away is that neither are going to be good enough to identify deepfakes as they continue to get more realistic.
Combating Deepfake Videos Using Blockchain and Smart Contracts describes an alternative to ML-based deepfake detection uses cryptography (signed requests and blockchain) to establish authenticity and provenance of media.
A Watermark for Large Language Models demonstrates an idea for watermarking text generated by LLMs.
Digital to Physical
It is natural that the most immediate beneficiaries of generative AI exist entirely in the digital realm; however, many of the applications will result in physical manifestations. For some potent ideas that come from the seamless coupling of bits and radical atoms (programmable materials that morph into shape in physical reality), learn about Hiroshi Ishii’s work at the MIT Media Lab.
The Room that Designed Itself is an Elle Decor article that brings the power of generative design into the world of designing the physical space with live, work and play in.

NASA is using generative AI to design parts for use in spacecraft. The field of generative design began as topological optimization for physical structures (using applications like Fusion 360) and now incorporates AI to iterate on a wider set of design parameters.
If we can engineer new machines and new buildings with generative AI—then a logical extension is to apply this to the complexity of an entire city. A so-called “smart city” could be generatively designed to maximize efficiency, aesthetics and well-being of all its citizens.
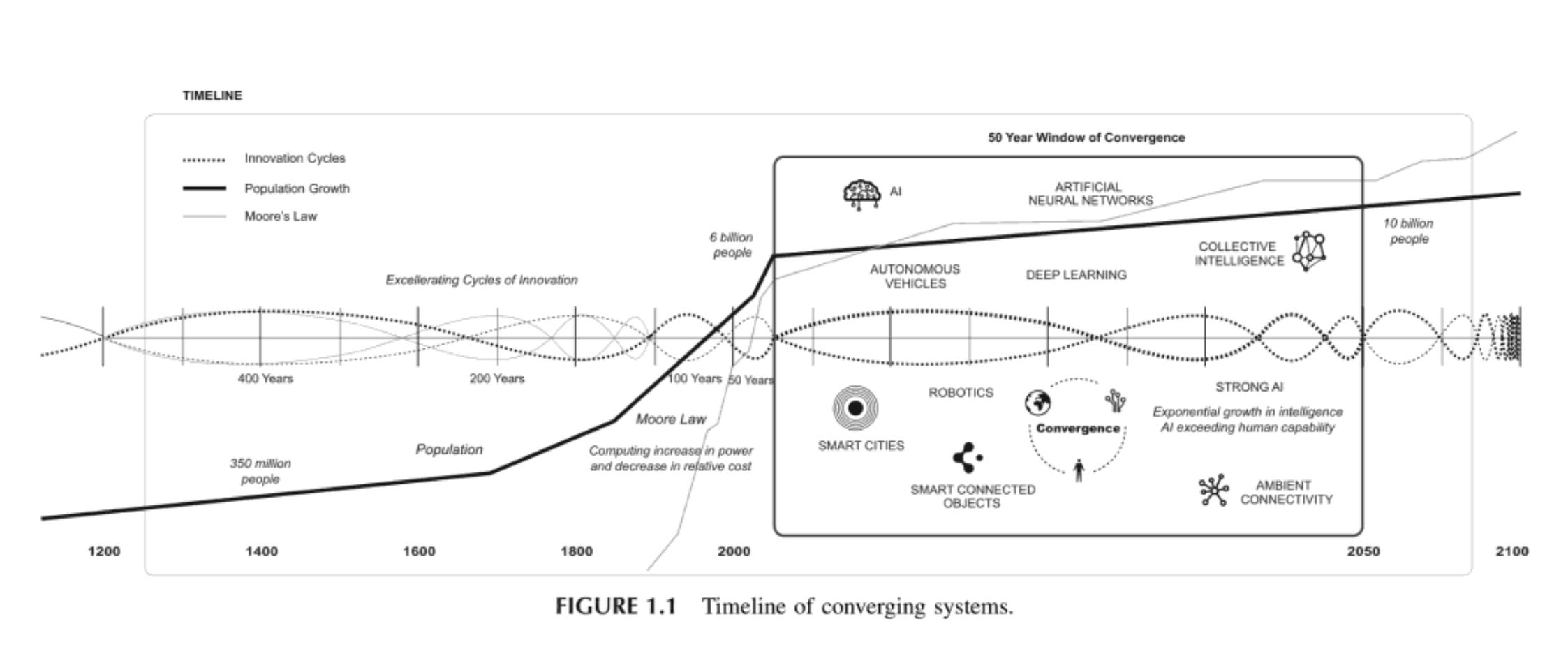
Why stop at cities? Why not entire nations? Jon Stokes comments on recent posts by Bali Srinivasan about decentralized AI. Will new "Network States" be designed to incorporate AGI? One would think generative AI would play a role in design, governance, labor and implementation.
Scale and Performance
The Scaling Hypothesis by Gwern explains why the innovations in artificial intelligence are being driven by leaps in the scale of our computational capacity (i.e., number of GPUs, FLOPs and networked machines to train models).
Emergent Abilities of Large Language Models explains how AI adding more parameters to models (i.e., increasing model size) has led to surprising new capabilities that are not present in smaller version of the same model.
Training Compute-Optimal Large Language Models addresses the fact that models are very data-hungry, and therefore while we invest new models we also need access to enough data to train them.
The Bitter Lesson by Sutton explains why general-purpose methods operating on scaled-up infrastructure have beaten specialized techniques.
Compute Trends Across Three Eras of Machine Learning by Sevilla et al illustrates the exponential growth (faster than Moore’s Law) of breakthroughs in AI applications as a result of scaled-up compute capacity.
Trends in GPU price-performance charts the rate of FLOPs per $ as doubling at a rate of every 2.5 years.
BIG-Bench is a benchmark (as of 2022) for comparing language models.
Qdrant (a vector database company) created a benchmark for comparing vector database performance (see the Vector Embeddings & Databases section below for more on this emerging category).
Road to AGI
Artificial General Intelligence (AGI) would be a general-purpose intelligent machine: you could pose a wide range of problems and it could solve them, as well as utilize other tools and information systems to reach conclusions. A capable-enough AGI could do the same things a human can. An AGI would become the ultimate generative AI—one able to produce any arbitrary set of intelligent outputs according to whatever inputs are prompted.
Will AGI be hard or simple? We don’t really know yet. But in this conversation between John Carmack and Lex Fridman, they favor simplicity:
Yann LeCunn notes that language models don’t really plan or reason. In another Twitter thread, he notes the importance of getting language models to work alongside tools like databases, calculators, etc. will be central to making the technology usable.
The Gato paper (Reed et al) describes a generalist agent that can do things like chat, use a robot arm, play Atari games.
Toolformer: Language Models Can Teach Themselves to Use Tools shows how an LLM can learn how to use software like spreadsheets or other programs via APIs.
What Learning Algorithm is In-Context Learning? Investigations with Linear Models explains that large language models can absorb and simulate other neural networks inside their hidden layers; in other words, LLMs can learn how to do new tasks from a small number of examples (less technical explanation on the MIT website).
Generative Agents
“Agents” or “action” AIs are those that have goal-directed behavior, can formulate plans, and have the ability to take actions. Some people see this approach as foundational to a true AGI.
A fairly comprehensive—yet beginner-friendly—overview of generative agents (AKA autonomous agents) is Matt Schlicht’s The Complete Beginners Guide To Autonomous Agents.
My conversation with Edward Saatchi discusses what sort of experiences in virtual worlds may someday be possible with generative, action-oriented AI beings.
Generative Agents: Interactive Simulacra of Human Behavior (Park et al) discusses is a paper in which characters were generated and placed into a virtual environment and allowed to interact with each other, resulting in a number of emergent behaviors.

The babyagi project by Yohei Nakajima uses GPT to establish its directs, iterates over a plan, uses a pinecone database to store its memory (more on that below) and can interact with websites.
Godmode (by Lonis) is a browser-based implementation of a generative agent that can do things like negotiate agreements, buy coffee or perform market analysis.
![[video-to-gif output image]](https://substackcdn.com/image/fetch/$s_!ASiX!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc07599bf-b53a-4a06-97a2-e0a428c748c4_600x375.gif "[video-to-gif output image]")
Auto-GPT is a generative agent that chains together “thoughts” from GPT and autonomously carries out instructions by visiting websites, storing plans—and in some forks, generates code.
Vector Embeddings & Databases
One of the key technologies underpinning generative agents as well as customized applications of language models is vector databases. This technology allows you to provide a memory to chatbots and AIs, as well as encode documents into their vector representations—which allows them to be semantically analyzed and queried. Vector databases are optimized for storing high dimensional vectors and performing queries based on similarity.
Dave Bergstein’s article, “Solving complex problems with vector databases” is a good overview of how vector databases work and the type of use cases they are optimized for.
The following (short) video is a good overview of the field:
If you’re ready to go hands-on with vector databases, embeddings and LangChain (a library for working with language models) — this how-to is a good guide for anyone who can find their way around a Jupyter notebook:
Using the above as a guide, I downloaded the Dungeons & Dragons SRD 5.1 into a queryable using OpenAI Embeddings, LangChain and Pinecone.
For a more technical treatment of the data platforms that will be important for AI/ML applications (including but not limited to vector databases), read Emerging Architectures for Modern Data Infrastructure.
Deep Learning & Transformers
Self-supervised learning: The dark matter of intelligence is a Meta AI blog post that explains the reason why deep learning works: within the hidden layers of models it is able to contain “intelligence” (the dark matter) that was previously resistant to directed algorithm development (the topic covered in the post is covered in an excellent Lex Fridman interview of LeCun).
Deep Learning (Yann LeCun, Yoshua Bengio & Geoffrey Hinton) is a survey paper from 2015 that reviews the AI technologies that existed before that time, in comparison to unsupervised learning methods that utilize multiple hidden layers (so-called “deep learning”). Although a lot has happened since 2015, this remains a good primer for the field, especially in understanding the inflection point that deep learning represents.
Collective intelligence for deep learning: A survey of recent developments (David Ha) is a survey of recent achievements in deep learning, emergent behavior, and opportunities to produce better results through methods inspired by collective intelligence.
Attention is All You Need (Vaswani et al) is the landmark paper that introduced the Transformer architecture, which is what’s led to a huge amount of progress in language models and many other applications. This is such an important paper that its title has become a meme within AI circles. It’s fairly technical, and dives straight into the math and algorithms—so if you want an excellent less-technical explanation, I highly recommend Yannic Kilcher’s video walkthrough. Xavier Amatriain also made a great catalog of transformer-based models.
Generative Adversarial Networks: an Overview describes GANs, which have played an important role in image synthesis as well as recognition tasks. GANs use a technique that involves training a network that generates an image, which then competes with a network that’s trained to discriminate images (detect which is a real example versus a generated version). Machine Learning Mastery has a less technical introduction to GANs.
Making the World Differentiable (Schmidhuber) is a 1990 paper that proposed self-supervised learning methods that map observable phenomena to differentiable functions, and then trains minimize errors (loss functions) via gradient descent. Although architectures have changed (transformers are relatively recent) this is the foundation of most neural networking approaches to AI in use today.
Theory & Mathematics
What is ChatGPT Doing and Why Does it Work (Wolfram) is worth mentioning for the second time in this roadmap: it’s a good place to begin if you want to start learning how these technologies actually work.
Andrej Karpathy’s Zero to Hero video series on neural networks is a great introduction that only assumes basic Python programing and high-school math. Another alternative is the neural networking courses on Fast.ai.
If you want a mathematically-oriented video explainer of how neural networks work, Grant Sanderson’s (3Blue1Brown) video series beginning with But what is a neural network? is a great starting point, and includes a good explainer on gradient descent.
Brilliant has a decent introductory course in neural networks and reinforcement learning (familiarity with basic matrix math is helpful to get through it, but they also have courses on that).
If you want to go deep on the mathematics and need either a refresher or want to level-up your understanding: there really aren’t any better instructors I’ve encountered than Sal Khan and Grant Sanderson. You’ll learn the actual (not simply conceptual) mathematics of gradient descent by the time you hit the middle of Grant’s multivariable calculus course on Khan Academy. If you need to learn the prerequisites like basic linear algebra or calculus (or trig, or matrices, or whatever) then you can just start learning from whatever works for you on Khan Academy. It’s free.
Mathematics for Machine Learning: Linear Algebra on Coursera is a good starting point for people who want to dive right into the math through the use of Python. However, I personally found that important mathematical subjects were glossed over in the rush towards code, so you’ll still find the Khan Academy materials above to be helpful in parallel.
If you get through the more mathematically-oriented and programmer-oriented courses above, you ought to be well-equipped to get through most of the research papers about machine learning (that doesn’t mean reading the papers is easy if this is entirely new to you, but you’ll at least be able to make sense of things.
Memes :)

The previous three memes were made by humans about AI. These were generated with AI using AI-Memer:

And while we’re on the subject of internet culture—did you know a GAN was made back in 2017 to generate new emoji?

Where next?
Because this is a rapidly-evolving field—one with many research papers published daily—I’ll update this regularly. What did I miss? Please share your thoughts in the comments, or drop me a message privately (you can also find me on LinkedIn and on Twitter).
An interesting application field is to help validate results or methodology bias of a research lab (here it’s been applied to a neuroscience debate on what’s the brain activity generating subjective experience). Do you have more material about that field ?
Refs :
https://www.nature.com/articles/s41562-021-01284-5
https://www.lemonde.fr/sciences/article/2023/10/02/neurosciences-une-joute-mondiale-sur-les-theories-de-la-conscience_6192035_1650684.html?lmd_medium=al&lmd_campaign=envoye-par-appli&lmd_creation=ios&lmd_source=default
Good