
Run Your Website with AI Agents
An agent publishes the pages. Another agent finds the gaps. The agent in the middle closes the loop. And running the loop ships features back to the codebase.

In December 2000, Computerworld ran a profile of me as the 27-year-old CTO of an enterprise content management company called Eprise. The opening of that piece was a story about my dad: when I was seven, he’d drive me into Digital Equipment Corporation, where he worked, and “plop me in front of a V-52 terminal.” I wrote my first program there. “An adventure game,” the article quotes me saying, “where you went through the mazes and avoiding monsters.”
The article then framed the rest of my career as a continuation of that game. By 2000 I was, in Computerworld‘s phrasing, “still in the business of running through mazes and avoiding monsters,” only the mazes were IT decisions and the monsters were competitors.
Twenty-six years later, the metaphor turns out to be more literal than the reporter meant. AI agents are exactly the things that navigate mazes and avoid monsters — search through state spaces, choose actions, recover from errors, find paths to goals. The same kind of program I wrote at age seven on a DEC terminal is now a category of software that runs companies. And one of those agents, today, runs my website.
That’s what this post is about.
Building Eprise to its IPO state took over two hundred people, sixty of them engineers, years of work, and tens of millions of dollars. The original codebase was C++ on top of whichever enterprise database the customer demanded (Microsoft SQL Server, Oracle, Sybase) and I wrote most of the original version. I’ve spent the twenty-five years since working in and around content systems. I know what they’re supposed to be. I also know what they cost.
This year I rebuilt the category alone. The result is LightCMS, a Go-powered, agent-first content management system that runs metavert.io and is MIT-licensed and open source. I wrote about its design intent in I Built a CMS for the Age of Agents earlier this year. This post is the catch-up: not “what’s in the repo” but what happens to the work itself when a website treats agents as first-class users.
Short version: the work stops looking like content work. I almost never open the admin UI anymore. Most of what used to be a half-day of clicking is now a paragraph of intent. Two of my projects talk to each other through agents and produce more useful pages than I could write by hand. And the act of running the system through agents has been the single best source of ideas for improving the system itself.
This is the post about that.
The shape of the project
LightCMS is, on disk, about 47,000 lines of production Go (closer to 70K if you count tests). It exposes 114 MCP toolsto agents across nine categories (content, templates, snippets, assets, search, settings, forks, comments, approvals) alongside a REST API at /api/v1/, a CLI, and an embedded Claude-powered chat widget that the public site uses. Storage is MongoDB. Search is hybrid (Voyage embeddings plus full-text), with reciprocal rank fusion. Deploy is Fly.io but the Dockerfile is portable.
That number (47,000 lines) is the right one to sit with for a moment, because it is simultaneously much smaller than what I’d have built in 2000 and much larger than what an outside reader assumes when they hear “weekend project.” Both things are true.
It’s smaller because almost nothing inside LightCMS is novel. MongoDB is the storage. Go’s standard library is the HTTP. Voyage does the embeddings. The hard parts that consumed the schedule at Eprise: building the storage layer, building search, building auth, building the asset pipeline (hell, I even wrote a String library back in the day!) all exist as cleanly factored services now. What’s left to write is the part that’s specifically a CMS: the template system, the publishing model, the version history with merge semantics, the wikilink-and-snippet syntax, the agent control surface. Forty-seven thousand lines is enough to do that well.
It’s larger than a weekend toy because I kept finding new things I wanted it to do. Forks. Approval workflows with a Contributor role. Webhooks with HMAC signatures. Scheduled publishing. ISR with edge cache headers. A site analytics dashboard. Each of those is a real feature, shipped because I needed it while running the system, not because a roadmap told me to. More on that loop in a minute.
The point isn’t the size of the codebase. The point is that a 60-engineer team’s worth of CMS now fits in one repo, and the operating surface (what agents see and do) is the part I actually spent my time designing.
I almost never open the admin UI
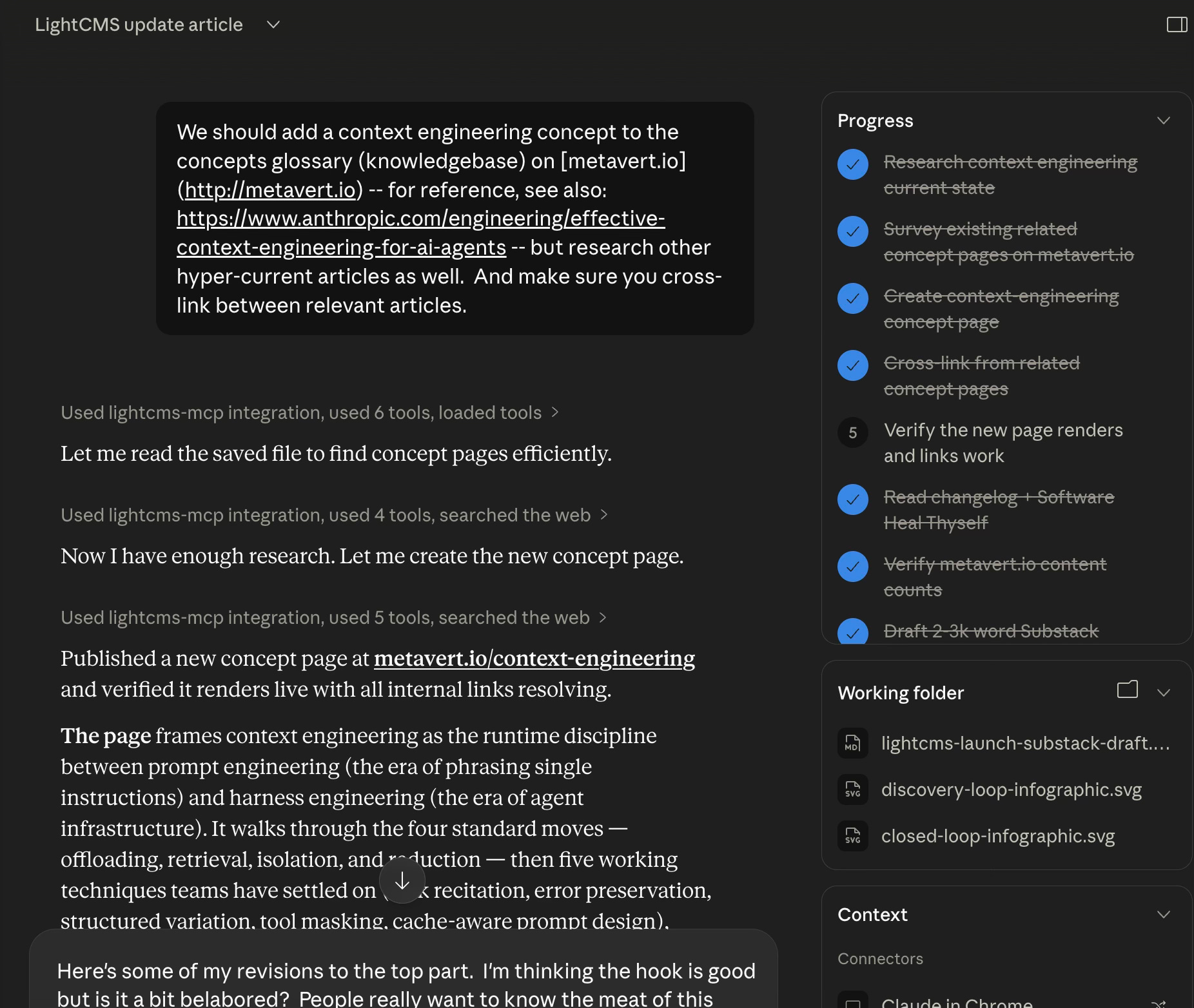
Earlier this week I wanted to add a new concept page to metavert.io: a definition of context engineering, the discipline that sits between prompt engineering and harness engineering. In a normal CMS workflow, this would have been: open the admin, find the right template, fill out the form, write the body, find every related page, edit each one to link to the new entry, save, publish, refresh.
In LightCMS, it was one paragraph of intent into Cowork. The agent searched the existing pages for related concepts. It found Prompt Engineering, Harness Engineering, Agent Harness, RAG, Tool Use, Context Windows, Agentic Memory, and a half-dozen others. It pulled the recent Anthropic, Manus, Phil Schmid, and Martin Fowler articles on context engineering and synthesized a definition. It published the new page. Then — and this is the part that matters — it updated seven existing pages to add reciprocal cross-links, converting inline mentions of “context engineering” into actual hyperlinks where the prose already used the phrase.
Total time: a few minutes. Total tool calls: about twenty-five. Total typing on my end: a paragraph.
The thing I want to dwell on isn’t the speed. It’s the graph maintenance. In a normal CMS, adding an entry to a glossary means writing the entry. The cross-links (the inbound edges of the knowledge graph) get added later if at all, by an editor who remembers to do it. In an agent-first CMS, the cross-links are part of the same operation. The graph stays connected because the agent is fast enough to make connectivity the default.
This is the mundane version of the magic. Not “AI wrote my blog post.” AI maintained the structure of my knowledge graph as a side-effect of writing my blog post. That’s the workflow change.
The same paragraph-of-intent pattern works from the CLI (lightcms is a Go binary), from Claude Code, from Claude Desktop, from any MCP-compatible client, and from a remote agent over OAuth-authenticated HTTP. The CMS doesn’t know which one you’re using and doesn’t care. The admin UI is a fallback now, not a primary surface.
Two MCPs, one agent, a closing loop
Here is the workflow that, more than any other single thing, has changed how I think about content.
I have another open-source project called llmopt, an AI Visibility Score platform that audits how LLMs and AI search engines perceive a brand. It produces reports, prioritized todos, gap analyses (”where are competitors cited and we aren’t”), and a 0–100 visibility score across six dimensions. It exposes its own MCP server with five tools: list domains, get reports, get the visibility score, list todos, update todos.
LightCMS exposes 114.
When a single agent connects to both, you get a closed-loop content system that I’m half-embarrassed to describe in print, because it works.
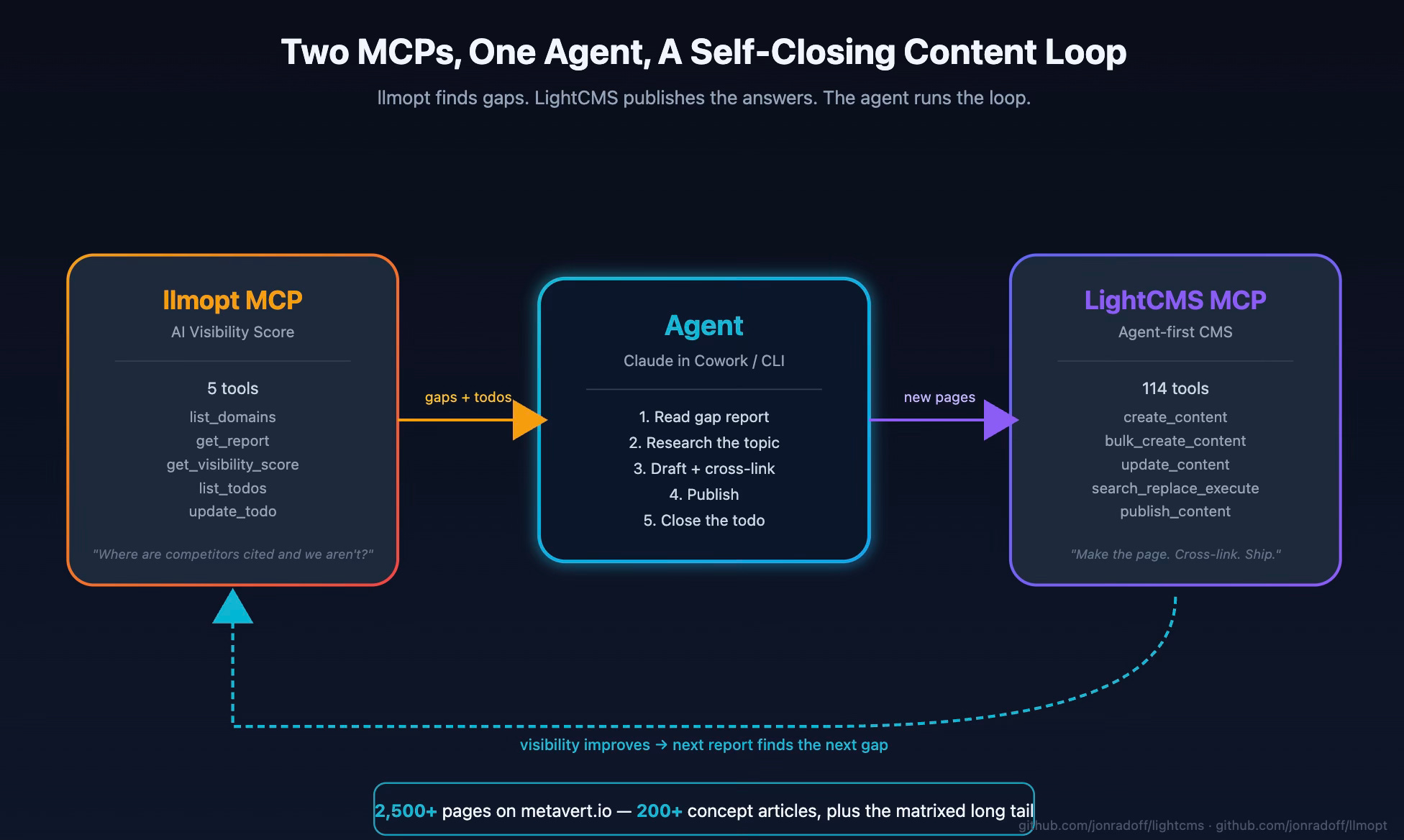
I keep this in a separate project I call metavert-seo. It’s a thin harness: a system prompt, a scheduler, a couple of guardrails. The actual work is two MCP servers calling each other through an agent in the middle. The agent reads the gap report, picks a topic, researches it, drafts a page using the right LightCMS template, cross-links it into the existing graph, publishes, then closes the llmopt todo. Repeat.
Here’s the thing the loop produces. The metavert.io knowledge base now has more than 2,500 pages. About 200 are core concept articles I think of as “the canonical glossary.” The rest is the matrixed long tail: company-vs-company comparison pages, industry-application syntheses (”AI Agents for Construction,” “Vector Search for Legal Document Discovery,” “Conversational AI for Retail” — there are dozens of these), explanatory deep dives, and the connective tissue between them. Every one of those pages is cross-linked, tagged, indexed for both full-text and semantic search, and reachable from the chat widget. Each one took me a single paragraph of intent; usually less, because the gap report itself names the topic.
This is where the thing I built stops being “a CMS” in the old sense and starts being a content engine that grows in directions my analytics tells it to. I’m not the author of most of those 2,500 pages in any traditional sense. I’m the one who set the themes, the voice, the templates, the link discipline. The agent fills in the matrix. The visibility score moves. The next gap report is different than the last one. The loop runs again.
Two open-source MCPs, one agent in the middle, and a content gap closing itself by Tuesday. That’s the workflow.
The intelligence is MCP’d, too
When the agent built the context-engineering page earlier this week, it didn’t guess which pages were “related.” It asked. Specifically, it called search_content (one of seven LightCMS MCP tools dedicated to search) which runs the same hybrid semantic-plus-full-text query that powers the public chat widget. The agent doing the writing uses the same intelligence layer the visitor reading uses. There is no second pipeline.
This is the recursion that turned out to matter most. Every piece of intelligence in LightCMS (semantic search, embedding reindex, link checking, audit log, analytics) is exposed as MCP tools, not just as user-facing features. The agent can introspect the system the same way a visitor can query it. The closed-loop content engine I just described doesn’t work without this; the agent’s ability to find related pages, detect broken links after a refactor, and read its own audit trail are how the loop knows what to do next.
A handful of features in the changelog came directly out of running this loop and noticing what was missing. A few highlights:
v1.4 — End-user search with hybrid RRF ranking. Originally added because I wanted the chat widget to be useful. The same MCP tools (
search_content,end_user_search) immediately became the way agents find relevant pages before writing or cross-linking. The chat widget and the SEO loop share the index.v2.1 — “Agentic API improvements.” Thirteen new MCP tools in a single release, every one of them traceable to a complaint Cowork had accumulated about its own daily work:
update_content_by_path(because looking up IDs was wasteful),scoped_search_replace_preview(because previewing before a destructive op should be the default), batch publish, content preview, asset-from-URL. Friction → feature, in one pass.v3.0 — Wikilinks, snippets,
lc:querydirectives, cascade regeneration. These are agent-shaped primitives.[[Page Title]]works because the agent doesn’t have to know URLs; it knows topics.[[include:cta-block]]works because the agent can compose pages out of named building blocks.lc:querylets a page declare itself as “everything tagged X” and update automatically when new X-tagged pages publish — so the agent doesn’t have to maintain index pages by hand.v3.1 — Bulk operations and regex search/replace. The cross-link maintenance pattern from the context-engineering example wasn’t possible before this. With
bulk_update_content(up to 100 items per call) andsearch_replace_execute, an agent can update an entire link graph in a single transactional sweep instead of looping page-by-page.v5.0 — Import pipeline (
import_markdown,import_csv, ten new MCP import tools). Built explicitly for agentic bulk content creation. Drop a directory of Markdown files, hand the agent a CSV of topics, and it imports cleanly. This is what made the SEO matrixed-content ramp work without me writing a custom ingestion script for every batch.v6.1 —
bulk_create_contentwith upsert mode, multi-pair search/replace. The most recent release and one of the most useful for the closed loop.bulk_create_contenttakes 100 items per call with parallel HTML generation;upsert: truemakes retries idempotent (eliminating the duplicate-key failure mode that used to wreck the loop on partial failures); multi-pair search/replace folds N rewrite rules into a single O(pages) pass instead of O(pairs × pages). All three came from running the loop at scale and watching exactly where it broke.
The pattern is consistent. Features in LightCMS aren’t shipped because they’re on a roadmap. They’re shipped because the agent that runs my website filed a complaint about not having them.
And the features that ship aren’t just user-facing — they’re MCP-facing, which means the next iteration of the loop can immediately use them. The platform’s intelligence isn’t bolted on. Semantic search isn’t a feature of the public site that happens to also have an internal API. It’s an MCP tool first. The public site is one consumer. The SEO loop is another. The agent that just published the page you’re reading is a third.
The chat widget is the same software that publishes the pages
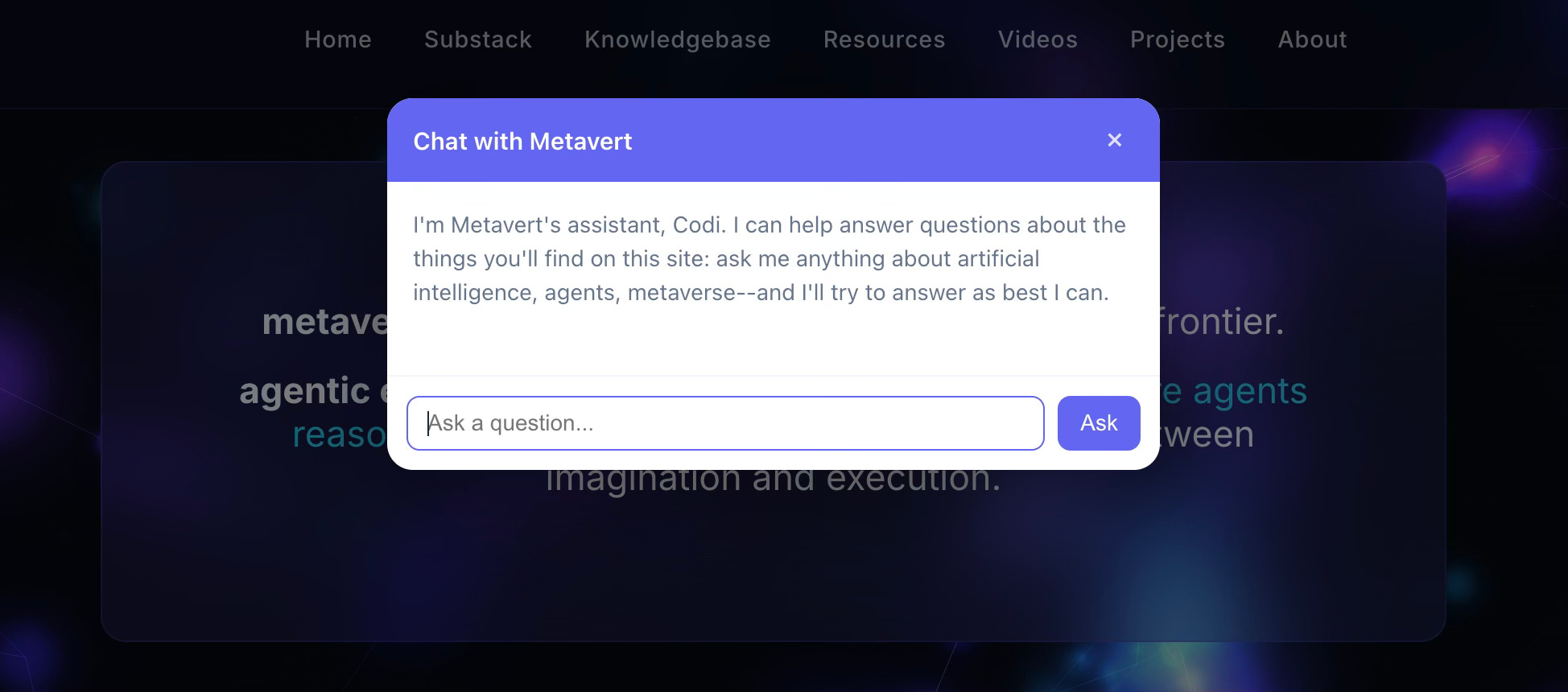
There’s a chat widget on metavert.io. Open any page, click the bubble in the corner, and you’re talking to Claude with the entire site in retrieval scope. It’s powered by the same Voyage embedding index that LightCMS already maintains for full-text and semantic search. The widget is a small front-end on top of an index that already had to exist.
What’s interesting isn’t that it works: most sites can stand up a chatbot in 2026. What’s interesting is that the same software that published every page is the software the visitor is talking to. The retrieval index isn’t a separate pipeline maintained by a separate team using a separate vendor. It’s a function of the publishing primitive.
When I publish a page, it gets embedded. When I edit, the embedding updates. When I delete, the embedding goes away. The chat experience and the editing experience are two views over the same data.
This is the AI-native pattern that doesn’t yet exist at most CMS vendors. They bolt chat on. LightCMS is the chat; it’s just also a CMS.
The strange loop: operating drives improvement
The previous section’s list of changelog items skipped over how those features got into the changelog. That’s the second-order effect I didn’t expect, and the one I think is most worth naming directly.
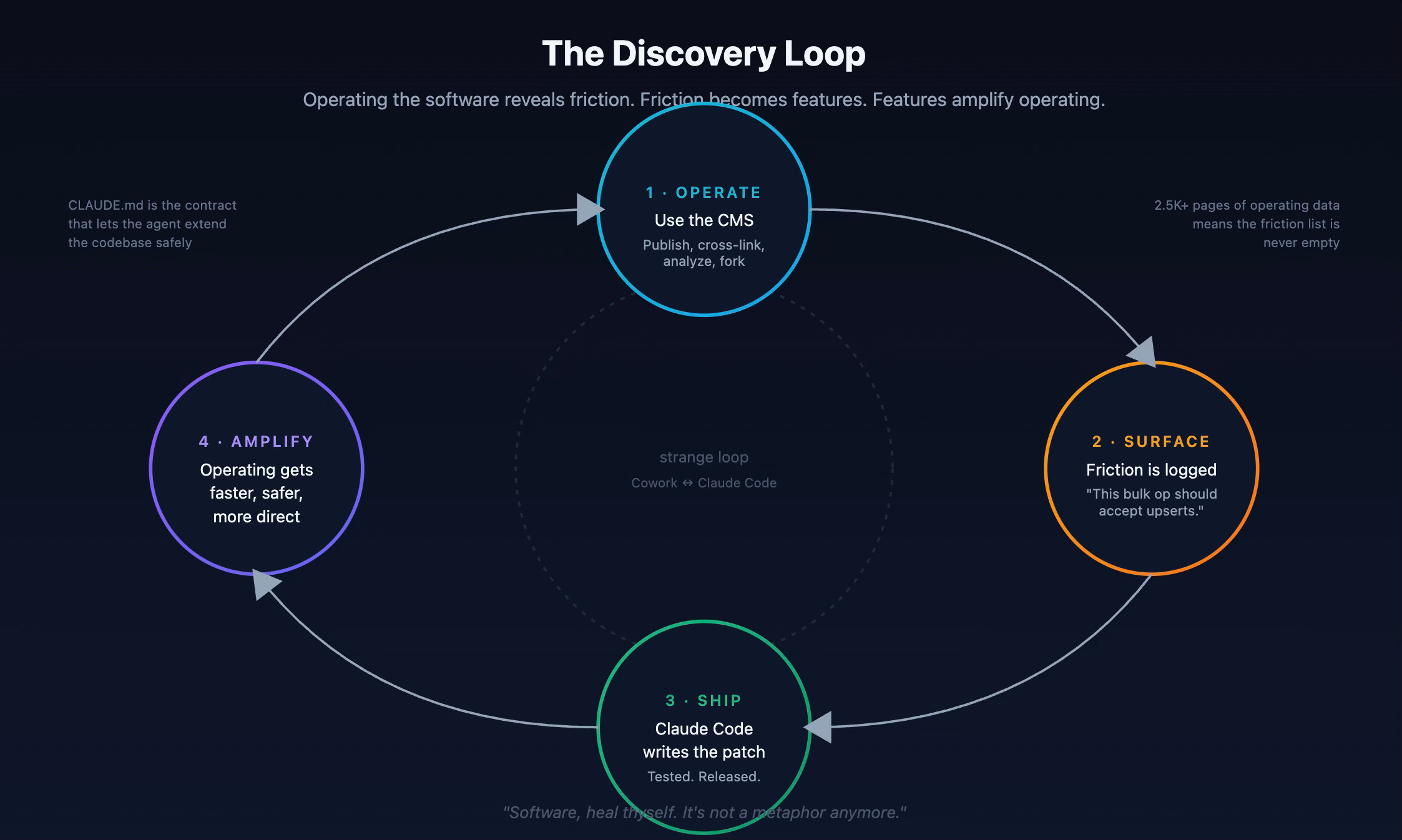
The mechanism is simple to describe and slightly uncanny to watch. I run a Cowork session driving LightCMS for an hour or two. Cowork accumulates a list of things that hurt: calls that took more round trips than they should, operations that needed preview-then-confirm safety, bulk endpoints that didn’t accept upserts and so retries failed loudly. I dump that list into a Claude Code session pointed at the LightCMS source. Claude Code reads the list, reads the relevant code, drafts a PR, runs the tests, and ships. The next day I run another Cowork session and the friction is gone. Frequently the agent doesn’t even need me to file the bug; it just notices.
This is the macro pattern, not just my pattern
The reason I think this loop is worth describing in detail is that it’s not local to LightCMS. It’s the shape the AI labs themselves have already adopted—and the shape every company building agent-first internal tooling is going to adopt over the next year or two.
Mike Krieger, Anthropic’s Chief Product Officer, said it plainly at the Cisco AI Summit in February:
Claude is now writing Claude… Right now for most products at Anthropic it’s effectively 100% just Claude writing.
Dario Amodei told Marc Benioff at Dreamforce last October that roughly 90% of Anthropic’s code is now AI-written. There’s reasonable debate about how to count those numbers: they include scaffolding, tests, throwaway scripts, debugging code, not only shipped product code—but the directional claim is on-record from the CEO and CPO of the company. The agent that operates Anthropic is the agent that improves Anthropic.
Sam Altman made the same claim at OpenAI DevDay 2025: Almost all new code written at OpenAI today is written by Codex users.
Codex users inside OpenAI ship 70% more PRs per week. The Agent Builder tool was shipped in under six weeks with Codex authoring an estimated 80% of its PRs. When GPT-5.3-Codex landed, it was the first OpenAI model the Codex team itself used to debug its own training, manage deployment, and diagnose evaluation results. Same loop: the agent that runs the platform is the agent that improves the platform.
The macro shift these quotes name is the one I want to point at directly.
The era of human-controlled UIs as the primary surface of software is ending. Humans still need dashboards: for control, orchestration, oversight, the moments where a person has to take responsibility—but the work itself increasingly happens between agents.
Coding agents iterate the source. Operating agents run the surface area. The loop between them is what actually moves the product forward. Humans set direction, audit outcomes, and intervene when the loop is doing the wrong thing. They’re not the bottleneck on every keystroke anymore.
This is where I think there’s a piece of strategy that most companies haven’t yet absorbed.
Every organization that’s paying attention in 2026 is building some version of a company brain: a unified, agent-mediated layer over its own knowledge, operations, customer interactions, and tooling. The framing most companies use is too modest. They describe it as “agents that surface the right information to the right person at the right time.” That’s the easy half. The hard and far more valuable half is that these agents are acting. They are building marketing funnels, generating campaign assets, drafting outbound, closing support tickets, identifying SEO gaps and filling them, debugging production incidents, writing the code that fixes the bug they just found. I’ve described two of those loops earlier in this post: a marketing-funnel loop (llmopt finds the gap, an agent through LightCMS publishes the page, the visibility score moves, the next gap report is different) and an engineering loop (Cowork operates LightCMS, Claude Code reads the friction list and ships the fix). Those aren’t future-state demos. They’re the workflow I run today.
Once you accept that the agents are acting—not reading, not summarizing, not retrieving, but operating—a second observation lands. Every action an agent takes is also a measurement of the system it took the action against. Every workaround the agent had to invent is a missing feature. Every operation that took three tool calls when it should have taken one is a roadmap item. Every pattern of repeated friction is a real-time signal about where to invest engineering time next.
If you treat that signal as a side-effect, you get a marginally better dashboard. If you wire it back into the agents and code that maintain the platform itself—into the coding agents that touch the source, into the MCP surface area that defines what acting agents are even capable of, into the company’s actual roadmap—you get a system that compounds. The acting agents become the source of intelligence about how to upgrade their own architecture. Friction becomes feature. Feature unlocks new actions. New actions surface new friction. The roadmap writes itself, with better priorities than any quarterly planning cycle has ever produced—because the priorities come from the work, not from the meeting where you guess at the work.
I’m one founder running this loop on a small open-source project. Anthropic is running it at scale on Claude itself. The companies that figure out how to run it on their own internal stack—not as a 2027 plan, but as a 2026 operating discipline—are the ones whose products will feel impossibly responsive a year from now. Everyone else will be building dashboards that humans politely ignore.
This is the strange loop. The same kind of agent that’s using the software is the kind of agent that’s improving the software. The CMS gets better because it’s used. I wrote about this pattern in detail in Software, Heal Thyself—there I focused on what it implies for software in general. Here I want to point at one specific artifact that makes it work.
The artifact is a file called CLAUDE.md. Most open-source projects ship a README.md that explains the project to humans. LightCMS ships a CLAUDE.md that explains the project to agents. It includes the build commands and the directory layout—but it also includes things you wouldn’t normally put in docs. “All website content operations MUST go through the MCP server.” The wikilink syntax. The autotagging convention (#tagname anywhere becomes a tag). The bulk-operation guarantees: 100 items per call, parallel workers, mandatory preview-then-confirm for search-replace. The role hierarchy. The conflict-detection rules for forks.
When a coding agent lands in the LightCMS repo cold, it reads CLAUDE.md and knows enough to safely extend the codebase within minutes. When a content agent connects to the MCP server, it reads the same file and knows enough to safely operate the site. CLAUDE.md is the contract that makes the discovery loop safe. Without it, you’d be one over-eager agent away from a corrupted database.
I think every serious open-source project will ship a CLAUDE.md (or its equivalent) inside the next year. It is documentation as API contract — for collaborators who read 200,000 tokens at a time and don’t get bored. The human reads the README once and skims it; the agent reads CLAUDE.md and actually does what it says.
What this changes about how I work
I want to name the change directly, because it’s the most important thing in the post and it’s easy to miss in a list of features.
The shape of content work used to be: a person opens a CMS, navigates around, types something, clicks publish. Maybe later they remember to add a few internal links. Maybe they update the related-articles list. Maybe a separate analytics tool tells them six weeks later that they should have written about a different topic entirely.
That shape is gone for me. The new shape looks like this:
I describe what I want. A paragraph, sometimes a sentence. “Add a concept page on context engineering with cross-links to the related concepts.” “Find the gaps in our coverage of supply-chain AI and write the missing comparison pages.” “Update every page that mentions Foundation Models to also link to the new Reasoning Models page.”
The agent does it. From the CLI, from Cowork, from Claude Code, from anything with an MCP client. The CMS doesn’t care which.
The receipts come back. URLs. Version comments. Audit log entries. Diff summaries. If the agent gets it wrong, I edit the result like it’s a draft from a colleague.
The cross-links, the embeddings, the analytics events, and the related-content graph all stay coherent, because they’re all functions of the same publishing primitive that the agent just called.
And every now and then, the agent files a complaint about its own work, which becomes a feature in the next release.
The granularity of my unit of work isn’t “an HTML edit” anymore. It’s an intent. The granularity of my product work isn’t “what do I build next,” it’s what frictions are surfacing in the operating data.
I dug up that Computerworld profile from 2000 to write the opening of this piece, and found a line I’d forgotten: the 27-year-old version of me telling the reporter:
“No matter how interesting something is, if I can delegate it, then I have to delegate it.”
I was talking about management discipline at a fast-growing company. The 53-year-old version of that instinct delegates to agents. Same discipline. Different operator. The whole arc of the last few months is that I figured out how to delegate the parts of my own work I always wanted to delegate but couldn’t, because there was nobody —and nothing—to delegate them to.
I don’t think this is the only valid future of CMSes. I do think it’s a strict superset of what every existing CMS is, and that the surrounding software stack: content systems, marketing tools, analytics dashboards, knowledge bases… All of these will all eventually adopt this shape, because once you’ve worked this way for a few weeks you genuinely cannot go back.
Star it. Fork it. Run it.
LightCMS is at github.com/jonradoff/lightcms. MIT licensed. Includes a docker-compose.yml, the CLAUDE.md agent manual, the full CHANGELOG.md, example templates, themes, and the same MCP server that runs metavert.io. There’s a remote MCP endpoint with OAuth so you can connect Cowork or Claude Desktop directly to a running instance.
If you’ve ever shipped a CMS, used a CMS, or run a content team, I’d genuinely like to know what you’d do with this. The interesting question for the next year isn’t whether AI can write a blog post; that’s settled…
It’s whether the surrounding software stack can stop pretending it lives in 2015 and start treating the agents reading and writing through it as first-class users.
I think it can. I built one to find out. Now I want to see what other people do with it.
⭐ Star the repo on GitHub: github.com/jonradoff/lightcms. Issues, pull requests, and angry feedback all welcome.
If you want to see the closed-loop SEO pattern in practice, llmopt is the other half. Both repos are MIT-licensed. Both expose MCP servers. Stand them up, point an agent at them, and watch a content backlog disappear.