
Software, Heal Thyself: Self-Improving Code
The strange loop where AI agents debug the tools they depend on

On Monday morning I asked an AI agent for its feedback on the software tool it was using to update my website. Then I handed the answer to a different AI agent to fix it. An hour or so later, the first agent was using the improved version and running verification tests. No human wrote a line of code. No human triaged a single bug. The software literally improved itself, through a feedback loop between two agents that each understood different aspects of the problem.
A few years ago, this would seem like magic.
This wasn’t a research experiment. It was just Monday.
I’ve been running my website, metavert.io, on LightCMS: the open-source content management system I built with Claude Code for the age of AI agents. The entire site is managed through conversation: I tell an AI agent what I want, and it creates pages, updates themes, publishes content. No dashboard, no forms, no page builder loading screens. This is the workflow I described in I Built a CMS for the Age of Agents: the website as conversation.
But something happened during a routine content update session that caught my attention. Something that shows us the future of software development.
The Wheels Within Wheels
Here’s what my typical website update looks like in 2026. I open Anthropic’s Cowork: a desktop AI agent that connects to LightCMS through MCP (the Model Context Protocol) — and I type something like: “Update the /lightcms page to reflect the latest version changes, and update the version history to match the changelog on GitHub.”
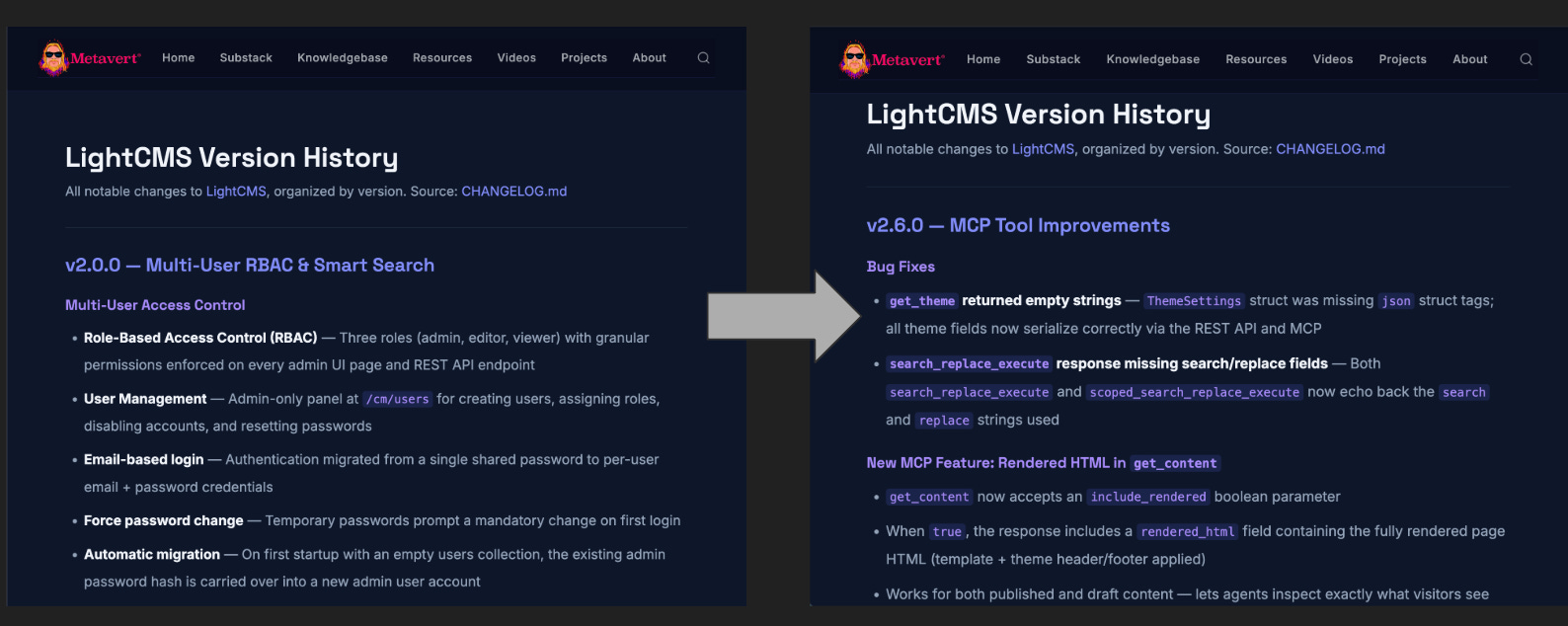
The agent takes it from there. It fetches the current page content, reads the changelog from GitHub, identifies what’s changed, crafts the updated HTML, publishes the pages, and then opens a browser tab to visually verify the rendering. The version history page went from documenting five releases to nine. The marketing page updated its tool count from 43 to 54 and added descriptions of every new feature. All through a single conversational prompt.
This is remarkable enough on its own. But the really interesting thing isn’t the update itself. It’s what happened before it.
“Based on Your Experience, What Would You Change?”
Over the course of several work sessions, I’d been watching Claude Cowork manage my website. It was capable, but I noticed friction. The agent sometimes needed three API calls where one should have sufficed. It would publish a page and then immediately open a browser to verify the rendering, because there was no way to preview content before making it live. Occasionally, a content update would silently reset the site’s theme to blank defaults, requiring the agent to perform a manual revert-and-regenerate dance after every single edit.
So I did something that felt natural but was, in retrospect, kind of extraordinary: I asked the operator agent for its improvement suggestions.
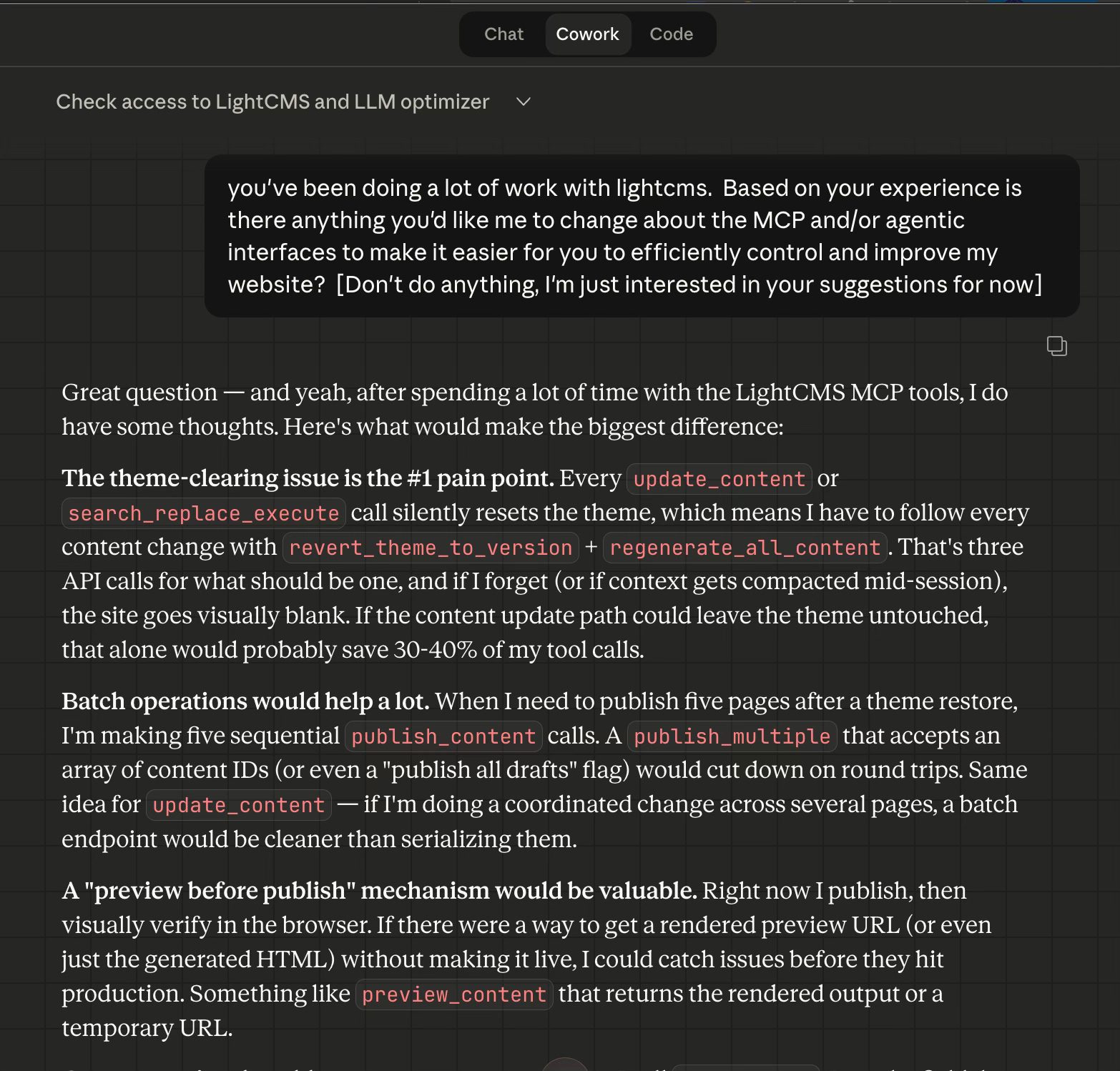
“You’ve been doing a lot of work with LightCMS. Based on your experience, is there anything you’d like me to change about the MCP and/or agentic interfaces to make it easier for you to efficiently control and improve my website?”
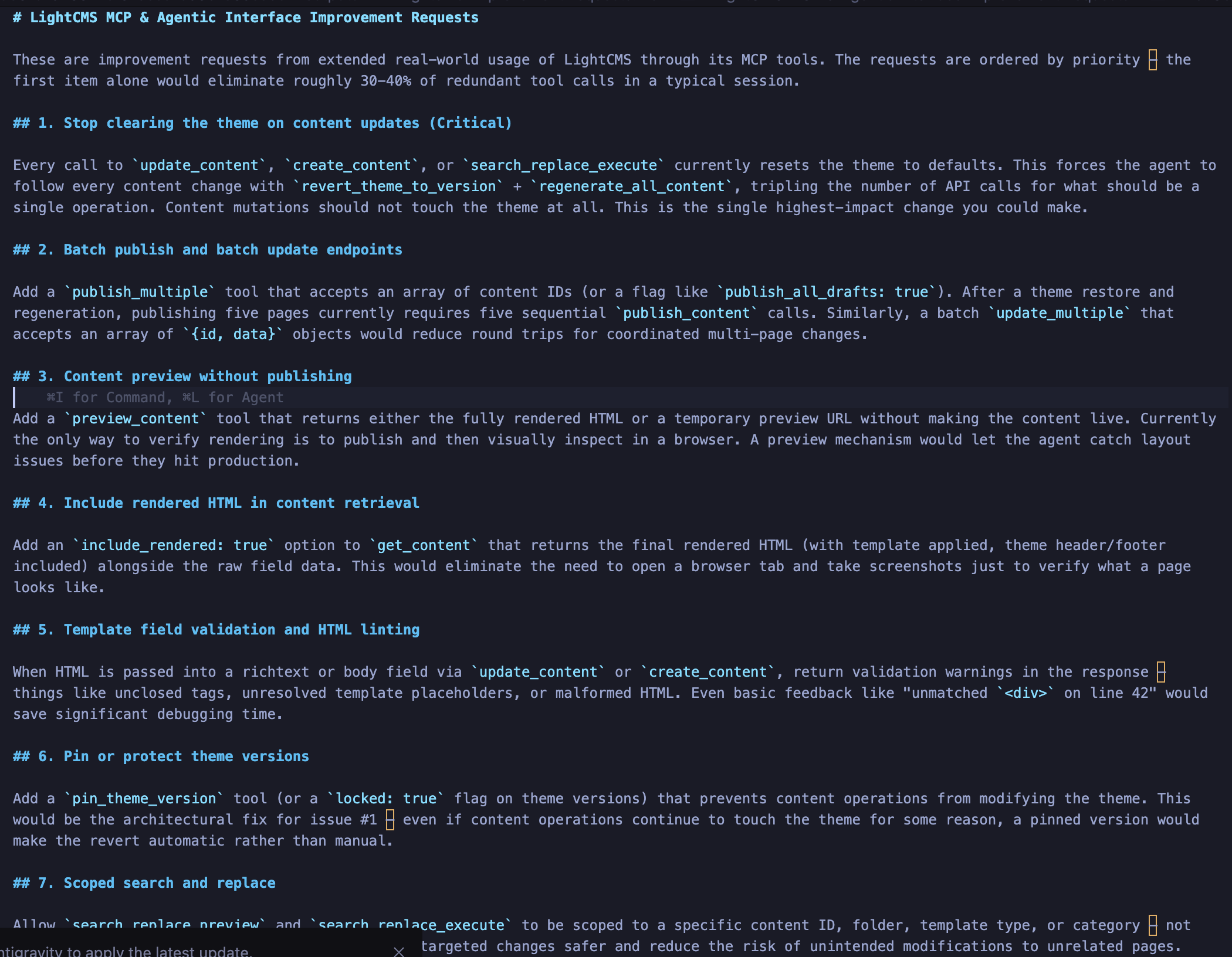
The response was immediate, specific, and prioritized by pain. Eight improvement requests, ordered by how much friction each one caused in practice:
The theme-clearing bug was flagged as critical: the agent estimated it accounted for 30–40% of redundant tool calls in a typical session. Batch publish was high priority because the agent was making five sequential publish calls after every theme restore. Content preview was requested because the only way to verify rendering was to publish first and then visually inspect in a browser. Theme version pinning was suggested as an architectural safeguard. Scoped search-and-replace was requested because site-wide replacement felt risky when the agent only needed to change content in one folder.
I then formatted these suggestions as a prompt and handed them to a completely different AI agent: Claude Code, which has access to the LightCMS source code.
Two Agents, Two Epistemologies
Here’s where the story gets interesting for anyone thinking about multi-agent systems.
I’d also previously asked Claude Code — the agent that built LightCMS — for its own suggestions on improving the agentic interfaces. It had a different perspective. Where Cowork’s suggestions were grounded in operational experience (”I had to do this three-step workaround every time I updated a page”), Claude Code’s suggestions were grounded in architectural analysis (”a batch endpoint would reduce round trips”).

Some ideas converged: both agents wanted batch operations, both wanted content preview, both wanted better tool descriptions. But there were critical divergences. The theme-clearing bug — which Cowork flagged as the single highest-priority issue, the one that was tripling its API calls and risking visual breakage on the live site — didn’t appear in Claude Code’s analysis at all. Claude Code had never operated the software in production. It had only built it. The bug was invisible from the inside.
This is, I think, a genuinely new epistemological pattern in software development. The operator agent has experiential knowledge (it knows what’s painful because it feels the pain). The code agent has architectural knowledge (it understands the system’s structure and can reason about what’s possible). Neither perspective alone is sufficient. The bug that mattered most was only visible to the agent doing the work.
The parallels to human organizations are immediate and obvious. How many critical bugs persist in production software because the developers who built it have never used it the way real users do? How many “minor inconveniences” turn out to be the friction that drives 40% of support tickets? The gap between building software and operating software has always existed. What’s new is that AI agents can bridge it—if you let them talk to each other.
The Fix
Claude Code took the improvement requests and went to work. In a single session, it implemented all eight changes and then some — 13 new MCP tools, taking the total from 41 to 54. Batch publish. Content preview with validation warnings. Scoped search-and-replace. Upload assets from URL. Theme version pinning. Update content by URL path instead of database ID. And the critical theme-clearing fix.
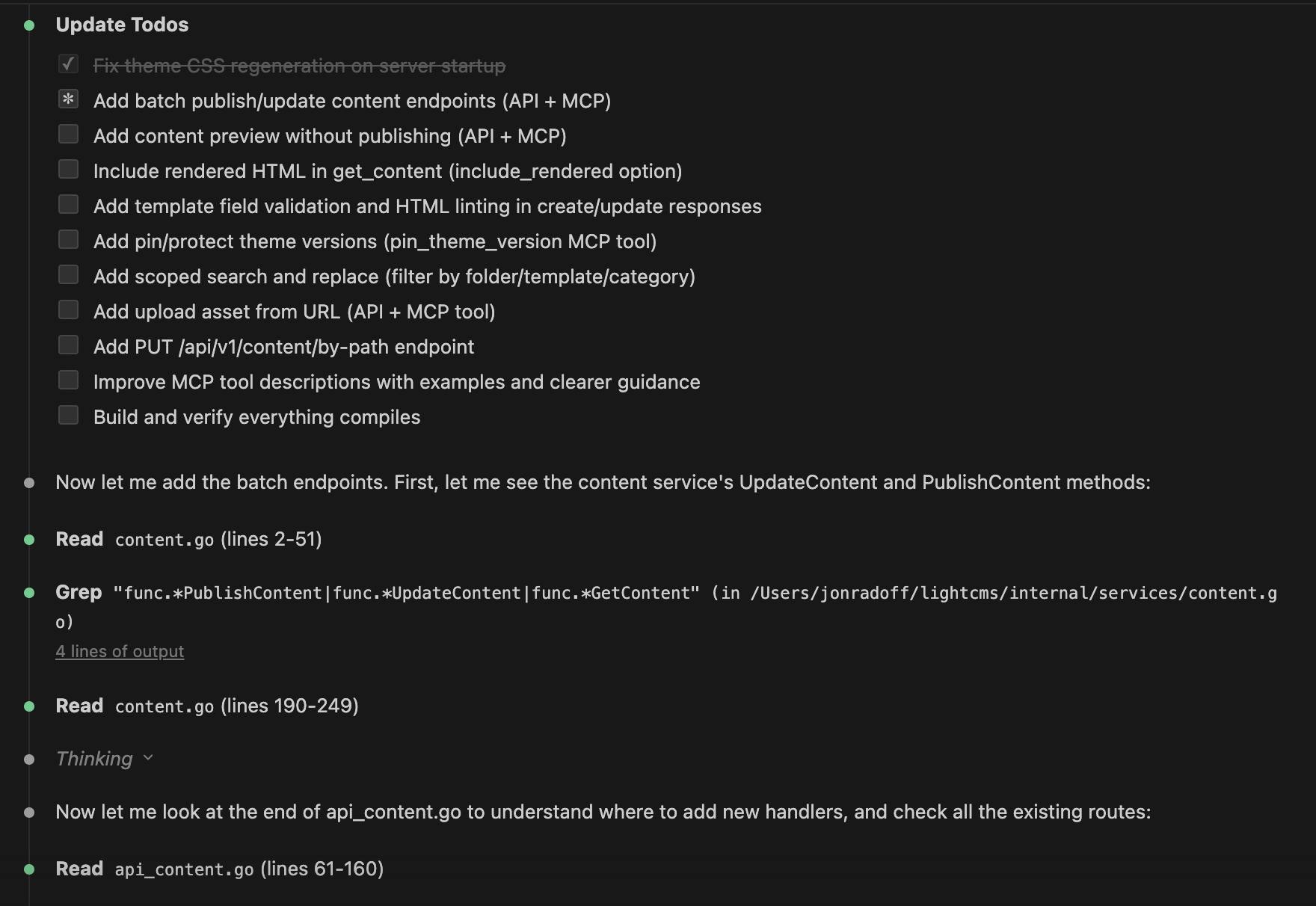
After deploying the new version, I reconnected Cowork and asked it to verify the changes. The agent ran a comprehensive non-destructive test suite: created a temporary test page, performed content updates, checked for theme side effects, tested the new preview endpoint, verified the search-replace response format, and cleaned up after itself. It confirmed the theme-clearing bug was fixed, all new tools were functional, and the workflow that previously required three API calls now required one.
Then came the real test: the version update session I described at the beginning of this article. Cowork used publish_multiple(the new batch publish tool) to publish both updated pages in a single call. It used get_content with the new include_rendered parameter to verify page content without opening a browser. The entire session was noticeably faster and cleaner than previous ones. The software had improved itself, and the improvement was immediately measurable in the operator agent’s efficiency.
The Autopoietic Loop
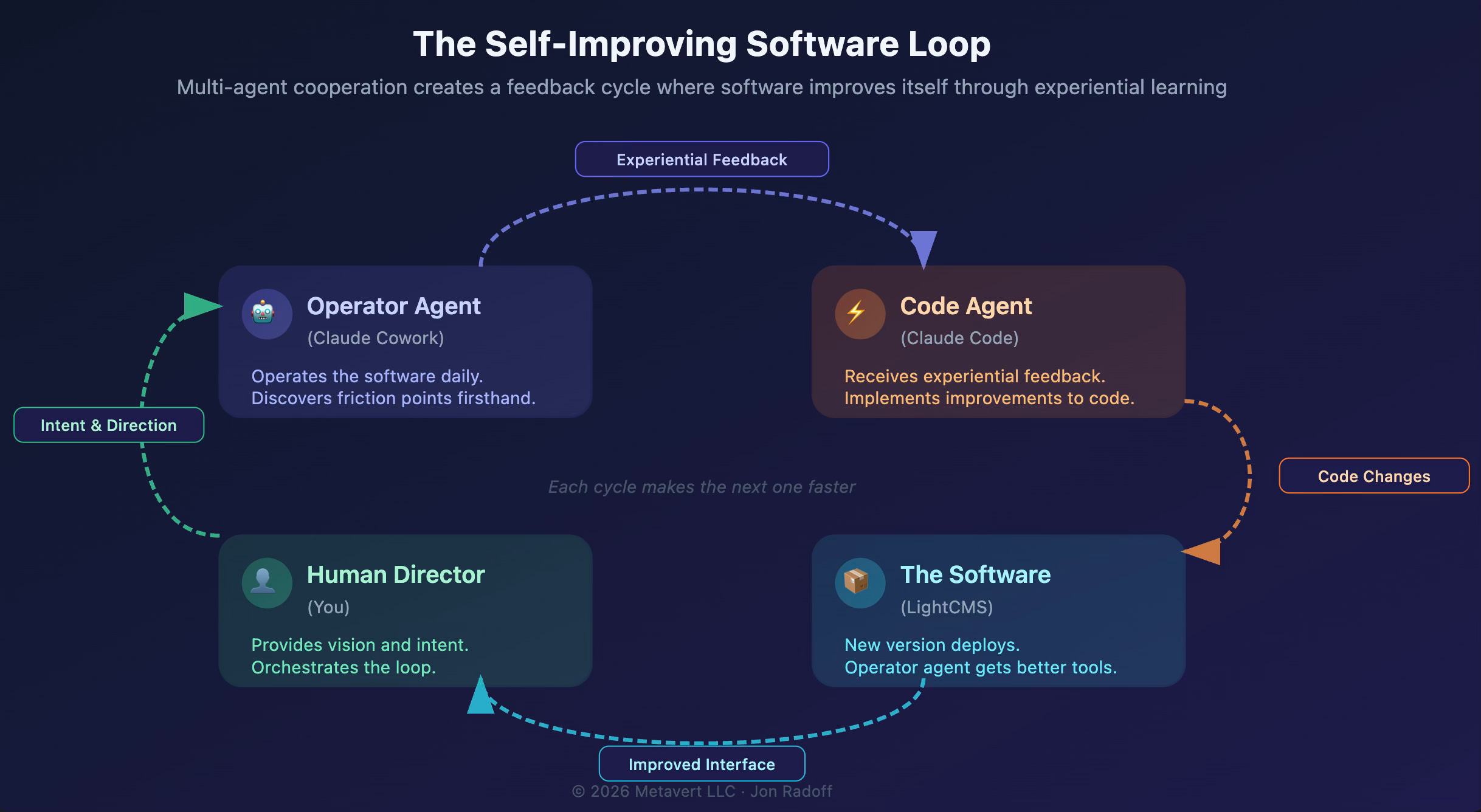
What I’ve described isn’t just a workflow. It’s a loop. And it’s a loop that gets tighter with every iteration.
Douglas Hofstadter called them strange loops1 — self-referential systems where moving through the levels of a hierarchy eventually brings you back to where you started, but transformed. Kenneth Reitz, writing about the recursive architecture of software and consciousness, put it in terms that resonate with what I watched happen to LightCMS:
I keep finding the same pattern everywhere: systems that only exist because they reference themselves. Not just reference — they create themselves through the act of self-reference.
— Kenneth Ruiz, Strange Loops All the Way Down
That’s exactly what’s happening here. The software’s operator generates the feedback that shapes the code that changes the software that the operator uses. You can’t point to where the loop begins.
The biological concept I keep returning to is autopoiesis: the property of systems that produce and maintain themselves. The term was coined by biologists Humberto Maturana and Francisco Varela in the 1970s to describe living cells: systems whose components participate in the very processes that produce those components. A cell manufactures the enzymes that synthesize the membranes that contain the enzymes. The system sustains itself through circular causation.

Software has never been autopoietic. It’s always required external agency (human developers) to maintain and improve it. But what I’m seeing with this multi-agent loop is something that rhymes with autopoiesis. The operator agent uses the software, discovers its limitations, produces improvement specifications, and those specifications get implemented by the code agent, producing a better version of the software that the operator agent then uses more effectively. The software isn’t fully self-producing. But the gap between “requires human intervention” and “generates its own improvement trajectory” has narrowed dramatically.
The human has become more of an orchestrator than a mechanic.
A recent article from Arize AI, “Closing the Loop: Coding Agents, Telemetry, and the Path to Self-Improving Software”(February 2026), describes a closely related pattern: systems that use telemetry and feedback loops to automatically improve their own prompts, error-handling, and code quality without constant human intervention. They call these “self-healing architectures” — systems with persistent memory that learn from operational errors and optimize themselves over time. What I’m describing goes a step further: not just a single agent healing itself, but two specialized agents cooperating to create improvements that neither could achieve alone.
The academic literature is catching up to this reality. A February 2026 paper, “Agyn: A Multi-Agent System for Team-Based Autonomous Code Generation”, describes structured multi-agent frameworks where different agents take distinct roles: researcher, coder, reviewer, tester. Each have role-specific model configurations. And a large-scale study by Liu et al. (2026) examines how frameworks like LangChain, CrewAI, and AutoGen are reshaping software development through multi-agent coordination. The ecosystem is growing fast: METR’s benchmark from February 2026 shows that AI agents can now sustain autonomous work for 14.5 hours, with that horizon doubling every 123 days.

But most of this research focuses on agents collaborating within a single task: multiple agents working together to write code, or to research and synthesize information. What I haven’t seen much of is the pattern I’ve been living with: agents collaborating across time and across roles, where one agent’s operational experience becomes the improvement specification for a different agent working on the underlying system. The operator-to-builder feedback loop.
The Convergence Pattern
This experience has made me think about a pattern I’m calling convergent multi-agent improvement. Here’s the structure:
1. An operator agent runs the software in production, accumulating experiential knowledge about friction, bugs, and inefficiencies. This knowledge is grounded, specific, and weighted by actual impact.
2. A code agent has architectural knowledge of the system. It can reason about what’s feasible, what’s elegant, and what’s risky. But it lacks operational context.
3. A human director orchestrates the loop, translating between the agents, making judgment calls about priorities, and deciding when to ship. The human provides the vision; the agents provide the implementation and the feedback.
4. The software itself is the shared artifact that both agents interact with — one from the outside (operating it), one from the inside (building it). Each iteration makes the software more fluent for agentic operation, which in turn makes the next iteration faster.
What makes this powerful is the complementarity of the two perspectives. In my experience, the operator agent found the critical bug (theme clearing) that the code agent was blind to. The code agent suggested architectural improvements (webhooks, event streams) that the operator agent hadn’t considered because it was focused on immediate pain. Together, they produced a better improvement plan than either would have generated alone.
This rhymes with something I wrote about in The Age of Machine Societies: when agents interact, the system-level behavior can differ significantly from what any individual agent was designed to do. The emergent property here is software that identifies and specifies its own improvements. No individual agent was designed to do that. But the loop between them produces it.
Why This Matters Beyond My Website
I’ve told this story through the lens of my own CMS because that’s where I lived it. But the pattern is general, and I think it’s going to become one of the defining dynamics of the creator era of software.
Consider what happens when this pattern scales:
Enterprise software could deploy operator agents that continuously use their own products the way customers do, generating improvement specifications grounded in real usage patterns rather than support ticket abstractions. The feedback loop from user experience to code change could tighten from weeks to hours.
Open-source projects could have contributor agents that both use and improve the codebase — submitting pull requests based on friction they encounter while performing real tasks. Imagine an agent that uses a library to build something, discovers an ergonomic problem in the API, and opens a PR to fix it — all autonomously.
Infrastructure platforms could use operator agents as continuous integration testers that don’t just verify correctness but evaluate usability — flagging APIs that require too many steps, documentation that’s ambiguous, or error messages that don’t help the caller recover.
The common thread is that software gets a nervous system. Not just logging and monitoring (which tells you what happened), but experiential feedback from agents that actually use the software as a tool (which tells you what shouldchange). The difference is the gap between a thermometer and a person who feels cold.
The reason this pattern can scale is composability. I’ve written before about how composability is the most powerful creative force in the universe: from biological systems to software to culture, composability creates power wherever there are means of aggregating, transmitting, and iterating components. That’s precisely the structure of this multi-agent loop: the operator agent aggregates experiential knowledge, MCP transmits it as structured feedback, and the code agent iterates on the codebase. Each element is modular and recombinable. Swap the operator agent for one that tests accessibility instead of content management. Swap the software for an API gateway or a design system.
The loop itself is composable; that’s why it generalizes.
When I wrote in Software’s Creator Era Has Arrived that “the gap between intention and implementation has collapsed,” I was thinking about human creators using AI to build software faster. But there’s a corollary: the gap between using software and improving software is also collapsing. And it’s collapsing because agents can occupy both sides of that gap simultaneously.
The Trust Curve
In my workflow, I’m still the orchestrator. I’m the one who decided to ask Cowork for suggestions. I’m the one who formatted the suggestions and handed them to Claude Code. I’m the one who decided to deploy the new version and asked Cowork to verify it. The loop required human judgment at every transition point.
But the transitions are getting smaller. In the history of abstraction: from machine code to assembly to high-level languages to AI-generated code. Each step starts with humans closely supervising the new layer, then gradually letting go as trust builds. Grace Hopper’s team created the first compiler in 1952; skeptics insisted real programmers would always need to write machine code directly. By the 1970s, almost nobody was writing assembly for business applications.
I suspect the same trust curve applies here. Today, I’m reviewing the improvement specifications before handing them to the code agent. Tomorrow, that handoff might be automatic, with the human reviewing only the final output. Eventually (not tomorrow, but not never) the loop might run autonomously, with human oversight focused on strategic direction rather than individual changes.
The key enabler is verifiability. I trusted the loop this time because Cowork ran verification tests after the deploy and confirmed everything worked. As verification becomes more sophisticated—not just “does it compile?” but “is the user experience better?”—the loop can tighten further.
What Comes Next
Every creative industry I’ve studied moves through the same phases: pioneers, engineers, creators. In Software’s Creator Era Has Arrived, I described how software itself is undergoing that transition. What I’m describing here is what the creator era looks like in practice — not just humans creating software through AI, but AI agents creating improvements to their own tools through experiential feedback loops.
The LightCMS story is a small example. But small examples are how paradigm shifts begin. The first compiler was less efficient than hand-written assembly. The first web browser was less capable than native applications. The first AI-generated code was less reliable than human-written code. Each of these started as a curiosity and became the default.
I’ll be watching this loop closely: not just in my own workflow, but across the broader ecosystem. The frameworks are emerging (CrewAI, AutoGen, LangGraph). The protocols are in place (MCP for tool access, A2A for inter-agent collaboration). The models are getting better at sustained autonomous work. And the economic incentive is clear: if an operator agent can identify a bug that wastes 40% of its API calls, and a code agent can fix that bug in a single session, that’s a direct, measurable improvement in the cost of running the software.
Software, heal thyself...
It’s not a metaphor anymore.
Further Reading
My earlier writing on the creator era and agentic architecture:
Software’s Creator Era Has Arrived: how the Pioneer→Engineering→Creator transition is hitting software itself.
I Built a CMS for the Age of Agents: the LightCMS project and the idea of websites as conversations.
The Agentic Web: Discovery, Commerce, and Creation: how agents are reshaping the web from pages to applications.
The Age of Machine Societies Has Begun: autonomous agents collaborating, competing, and transacting.
Composability is the Most Powerful Creative Force in the Universe: how aggregation, transmission, and iteration drive creativity from biology to software.
Multi-agent systems and self-improving software:
Kenneth Reitz, "Strange Loops All the Way Down" (September 2025) — The recursive architecture of awareness, from DNA to consciousness to code. Part of his Consciousness and AI series.
Multi-Agent Systems: overview on metavert.io of multi-agent architectures and frameworks.
LightCMS on GitHub: the open-source CMS at the center of this story. MIT licensed.
Arize AI, “Closing the Loop: Coding Agents, Telemetry, and the Path to Self-Improving Software” (February 2026) — Self-healing architectures and telemetry-driven improvement loops.
Liu et al., “A Large-Scale Study on the Development and Issues of Multi-Agent AI Systems”: Comprehensive analysis of LLM-based multi-agent frameworks.
Agyn: A Multi-Agent System for Team-Based Autonomous Code Generation: Role-based agent teams for autonomous software engineering.
METR Benchmark (February 2026): AI agent autonomous task horizons reaching 14.5 hours, doubling every 123 days.
Hofstadter’s Gödel, Escher, Bach (1979) and later I Am a Strange Loop (2007) explore how self-referential structures give rise to meaning and identity, from Gödel’s incompleteness theorems to the recursive patterns of consciousness. The concept maps surprisingly well onto software systems that participate in their own improvement: the loop isn’t a bug, it’s the mechanism.