
Web Renaissance Part 1: The Great Rebundling

This is the first in a three-part series about how the Web—as well as the broader Internet—is going to change over the coming months and years. It will be heavily informed by my experience in games, which I’ll write about a lot; but also by my earlier background as an early Web pioneer. If you're new to my substack, welcome! I write about the games, virtual worlds and the intersections with artificial intelligence, spatial computing and the metaverse.
The Web Renaissance is underway.
After years of gated systems and intermediaries, The Web is becoming more capable, faster and more user-centered.
The technologies driving this are artificial intelligence (especially large language models, or LLMs) along with new capabilities in web browsers (WebGPU, WebAssembly and Progressive Web Applications). Some of the largest incumbents are vulnerable to disruption for the first time in their history. New winners will emerge—and if it plays out as I hope, that will include consumers and more developers.
The three parts of this series are:
The Great Rebundling (what you’re reading now): how LLMs are fundamentally transforming the way we discover content and applications.
How the Web Could Eat Software: emerging technologies like WebGPU, WebAssembly and Progressive Web Applications are leveling-up the capabilities and performance of in-browser software. I’ll focus on games, since it demonstrates what has been hard for games for quite some time—but the lessons from gaming will extend to many other markets.
Web Innovation and its Opponents (coming soon): better tech and better browsers won’t be enough. Incumbents won’t cooperate with all aspects of the Web Renaissance, and new entrants won’t always mean they’ll make life easier. This will be the most prescriptive part of the series, again using gaming as a lesson in what has and hasn’t worked so far.
I hope the above preview give you a good reason to subscribe and join my community of developers, entrepreneurs and investors:
The Great Rebundling
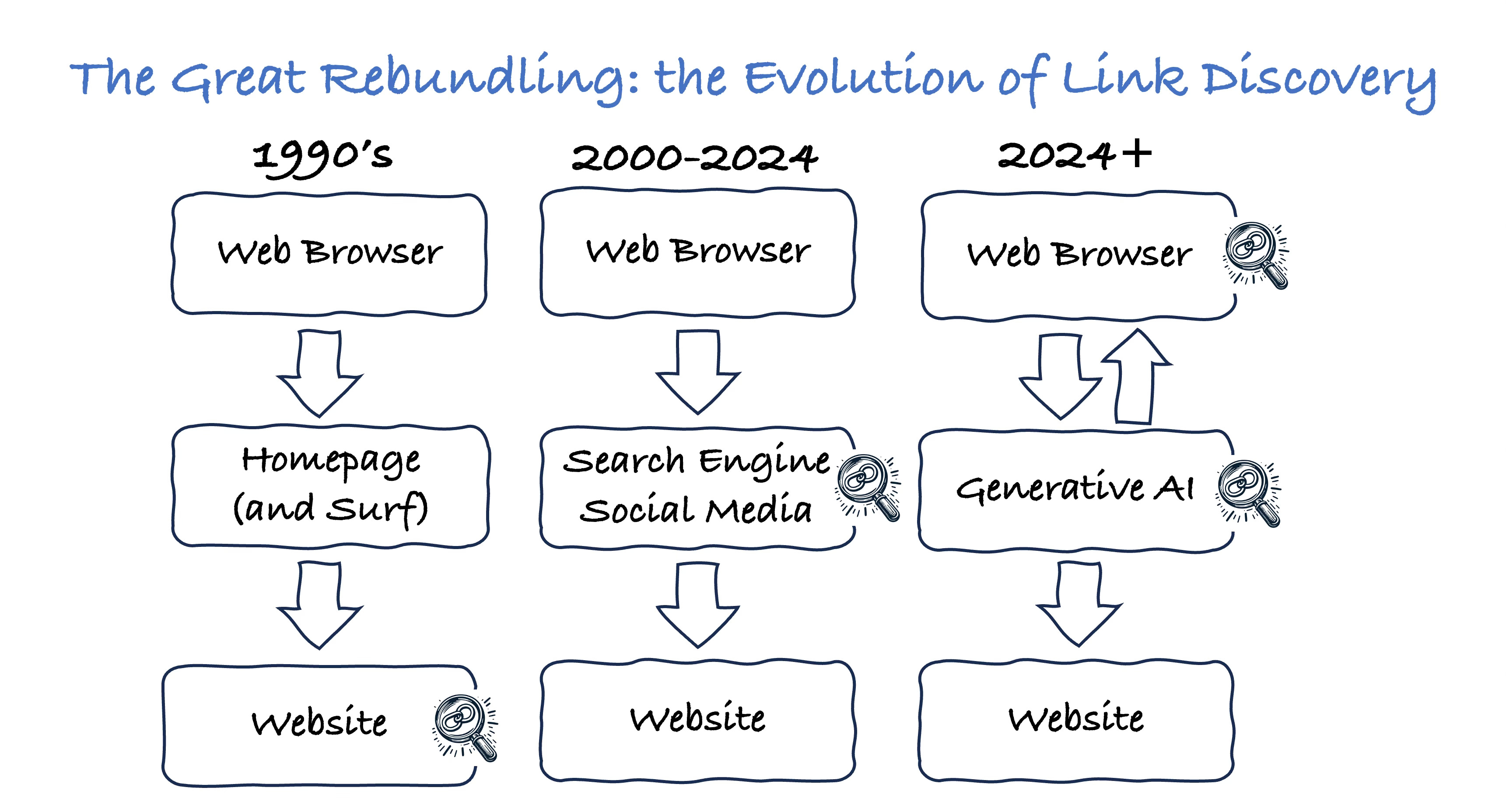
When the Web was born in the1990’s, people didn’t have great ways of discovering websites. It was mostly surfing the web: start the day at your homepage and link out from there, or save a few bookmarks for your favorites. Everyone competed to become your homepage.
Companies warred over distributing traffic on the internet. At first it was hierarchical catalogs of content (like Yahoo), and then early search engines (like Alta Vista), and then Google won that war through a focus on simplicity and speed. As a result, search engines (by which I mean Google, mostly) became the main way websites were discovered. It was natural to augment that with an advertising model. Along this same timeline, people largely shifted from web surfing towards social media—the other major way that websites are discovered.
With the emergence of search engines and social media, we no longer surfing destination websites. We start at Google or our preferred social site instead. These became an intermediating layer. This behavioral change completely reorganized the web, and gave rise to expertise such as SEO, SEM, influencers and social media marketers.
We’re now on the threshold of another fundamental shift. Most “search” will be replaced by a combination of chatbots and answer engines—and many questions will never even need to leave your web browser. This diagram shows the evolution of how discovering websites has changed over time, with the magnifying glass showing where this people usually start their discovery process:
LLMs and Generative AI
If you are one of the people who already use a chatbot powered by a large language model (LLM), you already know that you’re using search less. This is because many of your questions can be answered without the ads, clutter and time-consuming perusal that typically follows a search query.
LLMs still seem like magic (although becoming much more familiar). More importantly, OpenAI rediscovered the same thing Google did, which is that simplicity and answer-velocity is critical:

And it isn’t just search engines. It is also social media. One of the major use cases for social media (besides bragging, watching addicting videos or sharing photos) is when you ask your friends something. I suspect you’ll ask your friends less often1 if ChatGPT gives you better answers a lot faster.
Answer Engines
Sometimes hallucinations are a helpful feature of LLMs (as with with games and creativity). But sometimes you need accurate results to real-world questions. And in these cases, it’s powerful to have a chat session with an AI that’s supported by actual web pages you can drill-into for further information. This reorganization of search engines into answer engines is what Perplexity.ai has focused on:

Related content: watch my conversation with Aravind Srinivas, the founder/CEO of Perplexity.ai, when he was just starting up his answer engine company. For a discussion on when hallucination is a feature and not a bug, check out my conversation with Hilary Mason, CEO of Hidden Door.
In-Browser Generative AI
What if you never need to leave the built-in capabilities of your web browser to discover websites and answers? That’s the insight that Arc Search had. Using LLMs, it gives you a “Browse for Me” feature—which assembles the popular results and previews of many of the answers:

Currently, Arc Search is assembling its search results in the cloud; but that could also change. Open source LLMs and smaller, more optimized models may be able to accomplish results like this on your own device in the future. The momentum is towards more and more user-centered design, and potentially fewer intermediaries.
For more background on the thinking behind Arc Search, listen to the conversation with Josh Miller on the Hallway chat podcast. In particular, Nabeel makes a great point about why so little has fundamentally changed on web browsers2 over the years: because tech companies don’t ship software, they ship their entire org chart. Incumbents almost always favor their established business model (advertising, driven by search queries and video-consumption at Google) and hence they’ll be hesitant to make user-friendly improvements that subtract from revenue.
What’s Next
Search functionality is moving closer to the user through the combination of answer engines and in-browser AI. More software will move off-cloud and onto your device.
Many people have dreamt of the web browser becoming more like an operating system, a launchpad for all manner of software. With technologies like WebGPU and WebAssembly, we may finally may be close to that—which is what I’ll cover in the next part of this series:
How the Web Could Eat Software focuses on one of the most demanding categories of software that exists—games—to dive into how technologies are finally catching up to this vision.
Maybe “ChatGPT it” is becoming the reactionary answer to common-knowledge questions, in the same way that “Google it” became the answer to most online questions over the last two decades. It won’t go away though. Sometimes you just want to know what your own friends think. And maybe that’s an opportunity for personalized LLMs that incorporate social proofs from your social group.
I don’t mean to take away all the wonderful engineering that has gone into browsers over the last 20 years, because they’re faster and more capable than ever. It’s just that the way we use them hasn’t changed all that much… until now.
As usual, brilliant analysis & writing, Jon!
I agree with you. I’m curious what you think, as the “Answer Engine” moves closer to the user, how this looks in terms of protecting privacy and giving users control, and DID, especially in light of the new Internet protocol proposals from the UN &ITU (now called future, vertical communications networks, or FVCNs) which are essentially top down internets, with total censorship & tracking.
Freedom vs tyranny?