
When AI Learns to Paint: Three.js and Claude
Generative art, open-source graphics, and why the visual frontier is different

I’ve been writing about the Creator Era of software for a while now — the idea that natural language is becoming a compiler, that the bottleneck is shifting from implementation to imagination. But writing about it and living inside it are different things. So I decided to build something that would stress-test the thesis in one of the hardest possible domains: real-time 3D graphics.
The result is Threelab: an open-source generative art platform built on React, Three.js and Go. It includes a visual node-graph editor, a genetic evolution system, and a full MCP server that lets AI agents create, mutate, breed, and export 3D visualizations without a human touching a slider.
Scenes export as standalone HTML files, React components, or raw JSON. No build step. Open the file in a browser and it runs. Embed it on a website and it just works. Composability — the principle I keep returning to — made real.
This post is partly a project introduction, partly a report from the frontier of agentic creative development, and partly a set of observations about where graphics, game engines, and AI-assisted creation are heading. Some of it is encouraging. Some of it is humbling. All of it points to something bigger than any single tool.
The Platform: Threelab in 60 Seconds
Threelab ships 21 built-in patterns spanning mathematical curves (Lissajous figures, strange attractors, L-system fractals), physics simulations (cloth, flow fields, wave interference), GPU shader programs (physarum slime molds, reaction-diffusion systems, Mandelbrot fractals), and procedural geometry (voxel landscapes, Voronoi tessellations, circle packing).
Every pattern is implemented as a wirable node graph. You can inspect the logic, fork it, rewrite the evaluate function in a syntax-highlighted code editor, and watch changes hot-reload in real time. Stack multiple patterns as layers with blend modes, opacity, and bloom post-processing. It’s a creative playground that happens to be a node-based visual programming environment underneath.
But here’s what makes it interesting for the conversation about agentic software: Threelab exposes 13 MCP tools and a full REST API. An AI agent can browse the gallery, create a new scene by assembling a genome of pattern layers and parameters, evolve it through mutation and crossover, rate the results, and export a standalone HTML file — all programmatically. The agent doesn’t need to understand WebGL or Three.js internals. It speaks in genomes and intentions. The platform handles the rendering. Think of the genome as a high-level language for generative art — the agent never writes WebGL code directly.

This is what I mean when I talk about the agentic web — software that’s designed from the ground up to be operated by AI, not just used by humans through a GUI. The MCP server is a first-class citizen, not an afterthought bolted on.
Three.js: The Quiet Revolution
I chose Three.js for Threelab and I’d make the same choice again in a heartbeat. But the story of why is bigger than one project.
Three.js weekly NPM downloads have roughly doubled from 2.7 million to over 5.4 million in the past year alone — 270 times more than Babylon.js, 337 times more than PlayCanvas.1 Job listings requiring Three.js and WebGL skills jumped 25% in 2025. When WebGPU shipped across all major browsers in September 2025 — including Safari on iOS, the last major holdout — it unlocked 2–10x performance improvements for complex scenes, and Three.js was ready with zero-configuration WebGPU support from release r171 onward.2
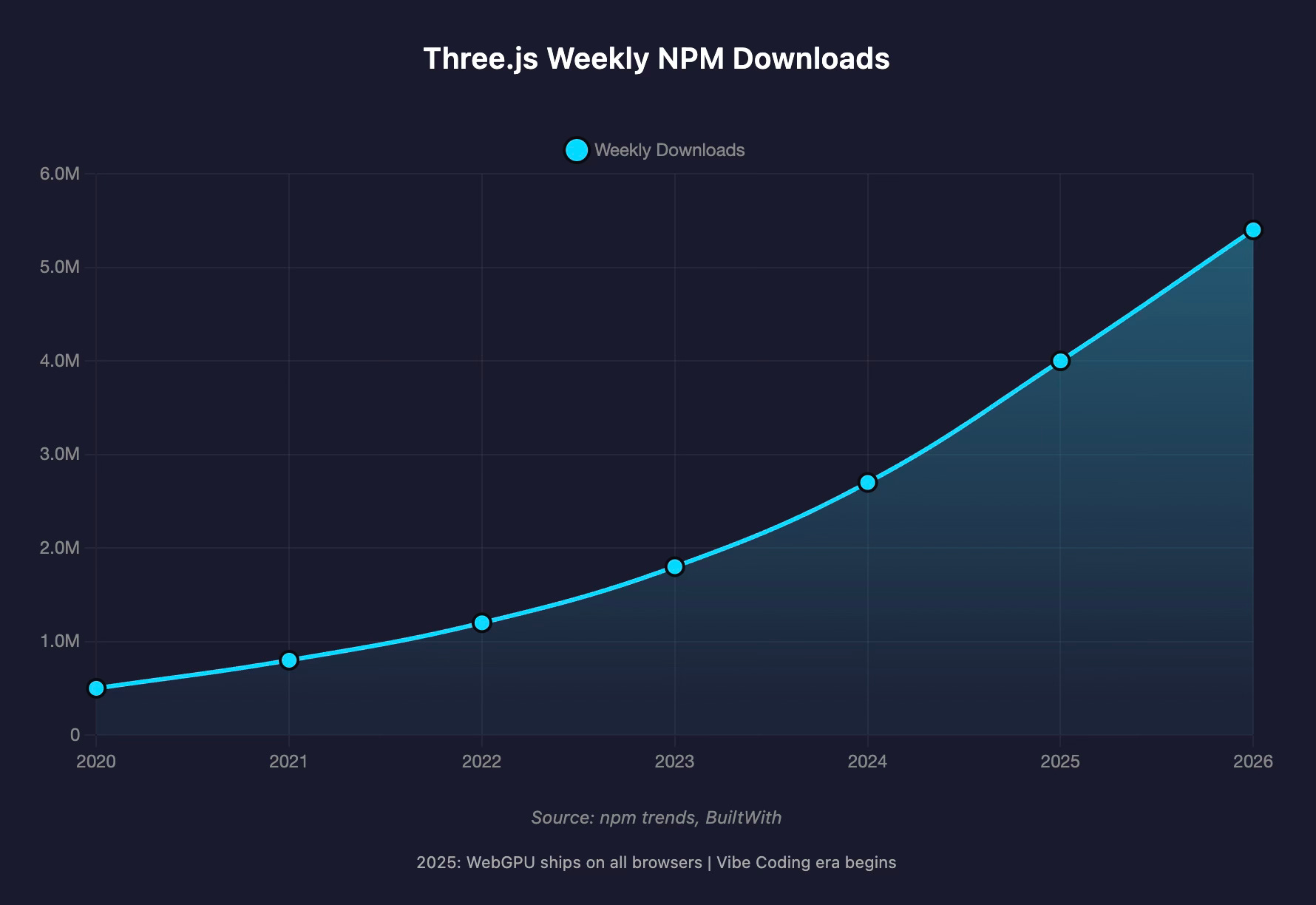
The HTML5 games market hit $3.2 billion in revenue, with JavaScript-based engines powering 89% of browser-based games. Three.js isn’t just a graphics library anymore. It’s the substrate of an entire creative economy.
And then came vibe coding.
The term Andrej Karpathy coined in February 2025 became Collins Dictionary’s Word of the Year by December. The Vibe Coding Game Jam drew over 1,000 submissions. Three.js turned out to be almost perfectly suited for this paradigm: simple setup (just JavaScript, no complex tooling), immediate visual feedback, and a forgiving API that abstracts away GPU complexity while still providing real power. As one analysis put it, Three.js in 2026 is defined by three shifts: “WebGPU becoming production-ready, AI-assisted development lowering the barrier to entry, and the library expanding beyond websites into physical installations.”3
The Open-Source Engine Question
Here’s where things get interesting — and where I think we’re watching a pattern that’s played out before.
At GDC 2026, for the first time in the survey’s history, Unreal Engine pulled ahead of Unity as the most-used primary engine: 42% to 30%, based on responses from over 2,300 game industry professionals. Godot, the open-source engine that W4 Games calls “the fastest-growing piece of game engine technology today,” captured 5% overall and 11% among newer indie developers.4
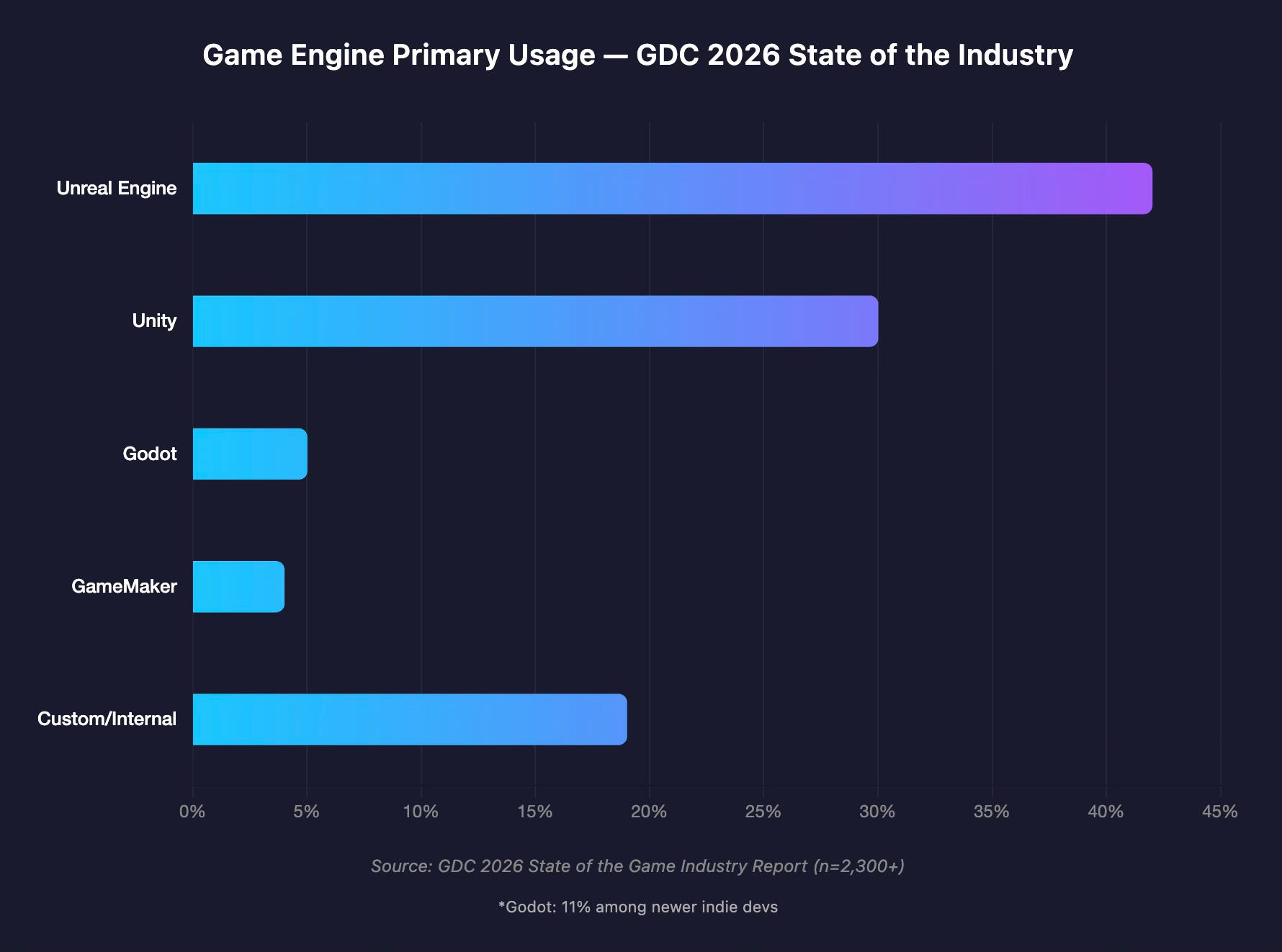
Unity’s story is particularly instructive. It still powers 51% of all games released on Steam in 2024 and dominates mobile with 71% of the top 1,000 mobile titles. But revenue tells a different story: only 26% of Steam revenue goes to Unity-built games, compared to 31% for Unreal and 41% for custom internal engines. Unity has been losing ground since 2021, pressured from above by Unreal Engine 5 capturing AAA and mid-tier studios, and from below by open-source alternatives attracting cost-sensitive indies.
The pricing controversy of 2023 accelerated something that was already in motion. When a platform provider changes the terms on its community, trust fractures — and developers start looking for exits that can’t be rug-pulled. Godot’s MIT license means no runtime fees, no revenue sharing, no forced splash screens, and — crucially — no foundation that can unilaterally change the terms, because the code is open source.
We’ve seen this movie before. Blender‘s trajectory in the 3D modeling space is the closest analogy. A decade ago, Autodesk Maya was the unquestioned industry standard — the tool you had to learn if you wanted to work in VFX, animation, or game art. Autodesk’s subscription model ($1,785/year) and ecosystem lock-in seemed unassailable. But Blender kept improving. Revenue for the Blender Development Fund grew 21% in 2024. What was once dismissed as an amateur’s tool is now used in professional production at studios worldwide. The gap has narrowed from “professional vs. amateur” to “two different philosophies of work.”5
Maya hasn’t disappeared — it retains strong positions in feature-film animation and VFX pipelines integrated with Houdini and Nuke. But its dominance is no longer unquestioned, and every year the calculus shifts a little further.
I think the same dynamics will play out with game engines, though the timeline and details will differ. A few distinctions matter here:
Three.js is not a game engine. It’s a general-purpose graphics library — a renderer and scene graph that makes no assumptions about physics, input handling, entity-component systems, or any of the other scaffolding that game engines provide. It’s closer to a creative materials supplier than a construction company. That’s a feature when your goal is composable web graphics; it’s a limitation when you need collision detection and AI pathfinding out of the box.
Godot is a game engine — and it’s the one I’d watch most closely. For platformers, RPGs, roguelikes, and visual novels, it has almost no weaknesses. Its 120MB editor, mature 2D pipeline, and zero license risk make it remarkably compelling for the kinds of games most indie developers actually ship. Its 3D capabilities still lag behind Unity for high-end work, and console porting requires third-party studios ($10K–50K), but these are narrowing gaps, not structural barriers.
Unreal may be the most protected of the incumbents, and for a specific reason: its strengths align tightly with the needs of current AAA development — photorealistic rendering, massive world streaming, Nanite geometry, Lumen lighting. Studios making $100M+ games need those capabilities and are willing to pay for them. Unreal’s moat is technical excellence at the high end, which is the hardest thing for open-source projects to replicate because it requires sustained investment in bleeding-edge R&D.
But the trend line is clear. Open-source tools are capturing the long tail first, then moving upmarket. It happened with Blender. It’s happening with Godot. And at the infrastructure layer, Three.js is quietly becoming the default way the web renders anything in 3D.
The Hard Part: Graphics Through the Eye of a Text Needle
Now for the honest part. Because building Threelab taught me something that tempered my enthusiasm about agentic development — at least in its current form.
Graphics-intensive work is significantly slower to iterate on with AI than text-oriented work. And this isn’t a minor friction — it’s a fundamental modality gap.
When I’m working with Claude Code on backend logic, API design, data transformations — anything primarily expressed in language and structure — the feedback loop is tight. I describe what I want, the agent implements it, I review the output, we iterate. It’s the workflow I described in my piece on self-improving code, and it genuinely feels like having a skilled collaborator.
But when I’m trying to adjust the visual appearance of a generative art pattern — the way particles trail through a flow field, or how bloom interacts with a Voronoi tessellation, or the precise feeling of a camera orbit — something breaks down. I find myself writing paragraphs to describe adjustments that a skilled graphics engineer would make in seconds by tweaking a number and watching the viewport. “Make the particles fade more gradually toward the edges, with a slight blue shift in the trail, and reduce the bloom bleed on the brightest points by about 20%” — this is an awkward, lossy translation of what is fundamentally a visual intention.
[📸 Screenshot: A before/after comparison of a flow field pattern showing the kind of subtle visual adjustment that requires extensive back-and-forth with an LLM]
A talented graphics engineer would have been 10x more productive than me on these specific tasks. Not because the AI lacks capability — Claude Code absolutely understands Three.js and shader mathematics — but because we’re forcing visual communication through a text bottleneck. It’s like directing a painter by writing letters instead of pointing at the canvas.
Recent research confirms this isn’t just a tooling problem — it’s a fundamental limitation. A 2025 survey on spatial reasoning in LLMs (presented at IJCAI 2025) found that “representational grounding — not linguistic fluency — remains the primary bottleneck.” Models struggle to maintain spatial relations when viewpoints shift; they lack anything resembling mental rotation. They can describe what they see, but they can’t think in the visual medium the way a human artist does. Put bluntly: LLMs are still more wordcel than shape rotator. The text channel is lossy in ways that matter enormously for aesthetic and spatial work.
The GDC 2026 sentiment data is striking here. Among visual and technical artists, 64% view generative AI as having a negative impact on the industry — the highest of any discipline. Game designers and narrative professionals aren’t far behind at 63%.6 I think this reflects something real beyond just job-security anxiety: the people who work most fluently in visual and spatial languages feel the modality mismatch most acutely. The sentiment shift is dramatic: negative views on AI’s industry impact went from 18% (2024) to 30% (2025) to 52% (2026), while positive views collapsed from 29% to just 7% over the same period.
The Frontier: Visual Languages for Visual Work
This points toward two avenues of development that I think will be transformative — and that aren’t getting enough attention relative to the rush to make text-based agents better at coding.
First: stronger multimodal understanding. Current vision-language models can describe images, answer questions about them, and perform visual reasoning tasks with increasing accuracy. Qwen3-VL-235B now rivals top proprietary models on multimodal benchmarks. But there’s a difference between understanding a visual and manipulating one with the fluency of a practitioner. When I show Claude a screenshot of my scene and say “the energy feels too dispersed”—that’s a visual-spatial-aesthetic judgment that requires translating back into parameter space. We’re getting better at this, but the gap between language-mediated visual reasoning and native visual thinking remains significant.7
Second: we need fundamentally different interfaces for visual-spatial collaboration with AI. Not better prompts. Not more screenshots. Something closer to a shared canvas where human and AI can point, sketch, annotate, and reshape in real time.
The earliest compelling prototype of this was tldraw‘s Make Real, which turned an infinite canvas into what Steve Ruiz calls “a conversation space where you and the AI can workshop an idea together.” You sketch, the model generates working code alongside your drawing, you mark up the result, and that markup becomes the next prompt. As Ruiz put it: “we accidentally made a really, really good visual multimodal prompting application.” The hard part, he noted, is getting information into the model, and “pictures are really good” at that.
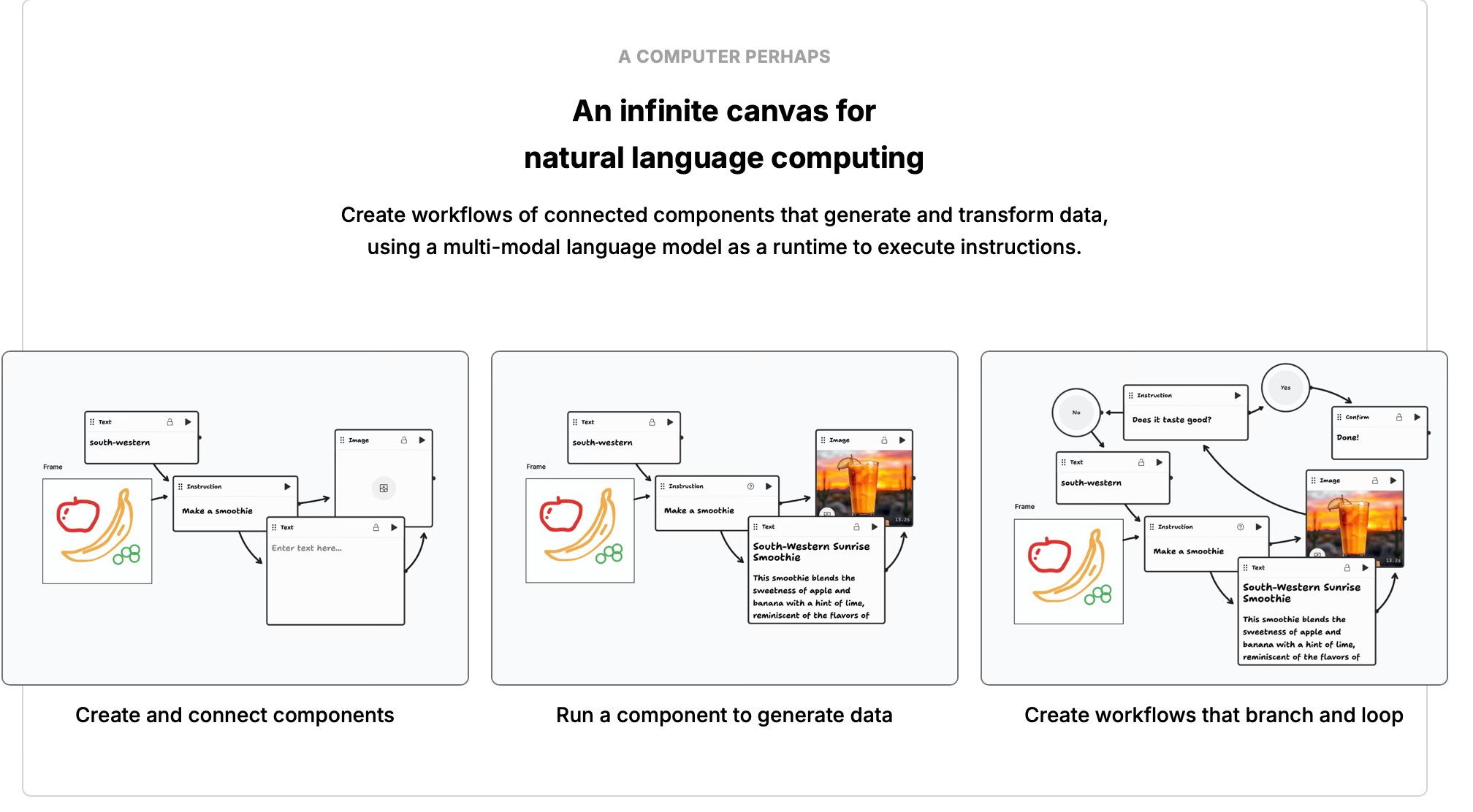
Since then, the idea has been evolving fast. TalkSketch (November 2025, from researchers at SUTD and Carnegie Mellon) pushes the paradigm further: designers sketch while speaking aloud, and both modalities feed into the AI simultaneously. Their user studies found that text-based interaction “often interrupts creative flow and creates a disconnect between ideation and sketching activities” — designers reported fatigue from “repeatedly typing long prompts to clarify their intent” and overwhelmingly preferred to just draw. TalkSketch’s insight is that speech and sketch together preserve the spontaneity of natural creative dialogue in a way that text prompting simply can’t.
Figma Make (powered by Claude) now turns designs into interactive prototypes, with an MCP server that lets code agents push and pull between canvas and codebase. Spellburst, from Stanford HAI and Replit, gets even closer to Threelab’s domain; it’s an LLM-powered canvas specifically for generative art, where artists prompt, get generated code, then use dynamic sliders to tweak parameters and can click the image to reveal and edit the underlying code directly.
And just this month, Stanford researchers published new findings on AI-artist collaboration. Professor Maneesh Agrawala was blunt: “while the models seem amazing, they are terrible collaborators.” The team’s work on establishing shared “ground rules” between human and AI—including ControlNet for spatial composition that mirrors how artists actually work, from rough blocking to fine detail—points toward a future where the model doesn’t just receive instructions but genuinely participates in a creative conversation.
But here’s what all of these have in common: they work in 2D. Flat layouts, component-based UIs, static images. Nobody has yet built the equivalent for 3D generative art, shader programming, or spatial creative work. When I’m trying to adjust how particles flow through a force field in Threelab, I can’t sketch my intent on a canvas and have the model understand the three-dimensional, time-varying, aesthetic adjustment I’m reaching for.
The visual conversation paradigm exists—but only for flat, component-based interfaces. Extending it into volumetric, dynamic, aesthetic space is the frontier that would change everything for creative 3D work.
Composability as Creative Principle
One of the design choices I’m proudest of in Threelab is the export system. Every scene — no matter how complex its layer stack, its evolved parameters, its bloom and camera settings — can be exported as a single HTML file that runs anywhere a browser runs. No dependencies. No build step. No server. Open it, and it renders.
This is composability made tangible. The exported artifact is a self-contained creative object that can be embedded in a blog post, dropped into a CMS, included in a presentation, or served from a static file host. It participates in the web’s native composition model: hyperlinks, iframes, script tags. It doesn’t need permission from a platform.
I’ve argued before that the open web is the natural substrate for the agentic era — that when AI systems generate software, they overwhelmingly generate web software (HTML, React, Node), making the browser the universal deployment surface. Over 90% of developers now use AI coding assistants regularly, and the output is web-native by default.
Threelab’s export system is a small but concrete instance of this principle. An AI agent can use the MCP tools to create a visualization, evolve it through several generations, and export a standalone HTML file — all without human intervention. That file can then be embedded anywhere on the web. The agent created a composable creative artifact that participates in the open web’s ecosystem.

When I think about where all of this heads — the convergence of agentic AI, open-source graphics tools, and the composable web — I keep returning to that phrase from my market map: the bottleneck isn’t engineering anymore. It’s imagination.
What Comes Next
I started Threelab as something between a creative toy and a technical experiment. What I found is that it’s actually a lens — a way of seeing where agentic creation works brilliantly and where it still breaks down, where open-source tooling is winning and where incumbents retain structural advantages, where the web’s composability model creates genuine leverage and where we need entirely new paradigms of human-AI collaboration.
The 21 patterns in Threelab — from Lorenz attractors spiraling through phase space to slime mold simulations self-organizing on a GPU — are beautiful in the way that mathematics is beautiful. They’re also, in a sense, the easy part. The hard and interesting work is making systems where AI agents and human creators can collaborate on visual, spatial, aesthetic problems with the same fluency they’re starting to achieve on text-based ones.

We’re building the tools for a creative era that doesn’t have a name yet. An era where software doesn’t just compute — it paints, it sculpts, it evolves. Where the browser isn’t just a document viewer but a canvas for generative art that an AI agent and a human being made together, each contributing what the other couldn’t.
The Three.js download counter crossed 5.4 million a week and it’s still climbing. Godot’s community doubles every year. Blender is teaching the industry that open tools win in the long run. And somewhere in the gap between a text prompt and a visual intention, there’s a new kind of interface waiting to be invented — one that speaks in shapes and colors and motion instead of words.
I think the people who build that interface will change everything.
Try Threelab for free: threelab.metavert.io
Threelab is open-source under the MIT license. The project, including full MCP server documentation and API reference, is available on GitHub. If you build something interesting with it, I’d love to see it.
Further Reading
Software’s Creator Era Has Arrived: my original piece on natural language as compiler, and why the bottleneck is shifting from implementation to imagination.
The Agentic Web: Discovery, Commerce, and Creation: when answers become applications and the open web becomes the natural substrate for AI-generated software.
Market Map of the Agentic Economy: a taxonomy for the era when software builds itself.
WebGPU Fundamentals: the next generation of browser graphics that’s unlocking the performance gains discussed in this piece.
npm trends: Three.js vs. Babylon.js vs. PlayCanvas: see the download gap for yourself.
Footnotes
npm trends data as of March 2026. Babylon.js downloads approximately 10,000/week; PlayCanvas approximately 8,000/week. The 270x gap is not new — Three.js has dominated the web 3D space for years — but the absolute growth rate has accelerated dramatically since WebGPU support and the vibe coding movement. ↩
WebGPU browser support timeline: Chrome/Edge since v113 (May 2023), Firefox since v139 (June 2025), Safari macOS since v26 (September 2025), Safari iOS since iOS 26 (September 2025). Early adopters have reported dramatic performance gains migrating from WebGL to WebGPU — in some cases up to 100x for GPU-compute-heavy workloads. ↩
From Utsubo’s “What Changed in Three.js 2026” analysis. The Vibe Coding Game Jam statistic comes from Hugging Face’s VibeGame project. Collins Dictionary’s Word of the Year 2025 selection is its own kind of cultural indicator — when the dictionary notices, a paradigm shift has already happened. ↩
GDC 2026 State of the Game Industry Report, based on 2,300+ respondents. The Unreal-over-Unity flip is notable because Unity had led this survey for years. Among AAA studios specifically, Unreal sits at 47%; among AA studios, 59%. ↩
The comparison to Blender is imperfect but instructive. Blender’s disruption of Maya (not complete displacement — Maya retains strong positions in VFX and feature animation) followed a pattern: free tool improves relentlessly → professional adoption grows at the margins → cost-conscious studios switch → ecosystem effects compound → incumbents lose pricing power. Autodesk’s Maya subscription at $1,785/year creates ongoing switching incentive every renewal cycle. The Blender Foundation’s 21% revenue growth in 2024 reflects corporate backing from studios that are actively investing in the alternative. ↩
GDC 2026 State of the Game Industry Report. The sentiment shift is dramatic: negative views on AI’s industry impact went from 18% (2024) to 30% (2025) to 52% (2026). Positive views collapsed from 29% to 13% to 7% over the same period. Game programmers sit at 59% negative. Only 36% of game studio employees use generative AI tools at all — lower than the 58% in publishing, marketing, and business roles. ↩
The multimodal benchmark landscape is evolving quickly. MMMU Pro (academic visual reasoning) and LM Arena Vision (human preference) are the current standard evaluation frameworks. The gap I’m describing isn’t about benchmark performance — it’s about the difference between analytical visual understanding and creative visual manipulation, which is harder to measure and harder to achieve. ↩
All I can say is wow, so freaking cool. Thanks for making this and sharing it!