
Ship Your Strategy
Why the full-stack product manager will define the agentic AI era

Your product strategy deck is a liability. While you’re aligning stakeholders on a roadmap, someone is shipping your roadmap as a working prototype with three agents and a weekend.
This isn’t a provocation for its own sake. It’s a description of reality in March 2026.
LinkedIn just replaced its Associate Product Manager program with “Associate Product Builder,” a role that combines code, design, and product management into a single function. Microsoft and Citi are creating dedicated “agent ops” teams to manage fleets of AI agents. And according to recent developer surveys, 41% of all code committed to production is now AI-generated, with 92% of US developers using AI coding tools daily.

Something fundamental has shifted. Not in the tools we use, but in the velocity at which strategy can become product. And that shift is rewriting what it means to be a product manager. The PM role isn’t dying; it’s expanding into something I call the Full-Stack Product Manager: a product leader who doesn’t just coordinate between strategy and engineering, but operates fluidly across both, using AI agents as force multipliers across the entire product lifecycle.
This isn’t about adding AI features to your product. It isn’t about hiring a prompt engineer or bolting a copilot onto your existing workflow. It’s about recognizing that the entire loop—from strategic insight to shipped product to market feedback—can now collapse from quarters into days.
The product leaders who understand this will define the next era. The ones who don’t will spend the next year perfecting a strategy deck for a product that someone else already shipped.
The $285 Billion Wake-Up Call
In February 2026, the software industry lost $285 billion in market value. Most analysts called it a correction. It wasn’t. It was structural.
The SaaS model—built on per-seat licensing, integration complexity as a moat, and incremental feature development—is being unwound by a simple reality: AI agents don’t need seats. They don’t need onboarding. And they increasingly don’t need the software at all.
The threat to Asana isn’t that AI makes Asana easier to use. The threat is that an AI agent can manage your project without Asana. The threat to Salesforce isn’t a better copilot. It’s that an agent can orchestrate your entire sales pipeline by composing smaller, cheaper primitives; CRM becomes an implementation detail, not a product category.
This is what I’ve described elsewhere as the shift from the Engineering Era to the Creator Era. Language models have become compilers for natural language, translating intent into implementation the way Fortran once translated mathematics into machine code.1 The winners aren’t the companies with the best features. They’re the ones who understand that entire categories of software are being absorbed into agent workflows — and are positioning accordingly.
Naval Ravikant observed that “vibe coding is the new product management.” He was right about the direction but underestimated the magnitude. Vibe coding doesn’t replace product management. It subsumes it, absorbing specification, prototyping, testing, and initial deployment into a single fluid workflow that one person with the right strategic instincts can drive.
The companies that are winning right now—Cursor hitting $1 billion ARR in 24 months, Lovable reaching $20M ARR with explosive growth among non-technical founders—aren’t just AI-enhanced versions of older tools. They’re built on the assumption that the distance between “I want to build this” and “this is running in production” is measured in hours, not quarters.
Which raises the question: if strategy can be shipped, and products can be prototyped in hours instead of months, what does product leadership actually look like?
The Full-Stack Product Manager
The traditional product manager coordinates. They write PRDs, align stakeholders, prioritize backlogs, and hand specifications to engineering. In the agentic era, that workflow is a bottleneck.
The full-stack PM doesn’t just manage the product process; they operate within it.
They prototype strategy directly. They deploy agents to gather competitive intelligence autonomously. They build feedback systems that cycle user insights into shipped features in hours, not sprints. And they treat AI-driven discoverability as a first-class product concern, not a marketing afterthought.
This isn’t about one person doing everything. It’s about the PM role expanding to absorb capabilities that used to live in separate functions — and, crucially, about software engineers with strong product instincts moving into this expanded role. When the distance between “I think we should build this” and “here’s a working prototype” collapses to a conversation with an agent, the line between product management and product development dissolves. The full-stack PM lives in that dissolved space.
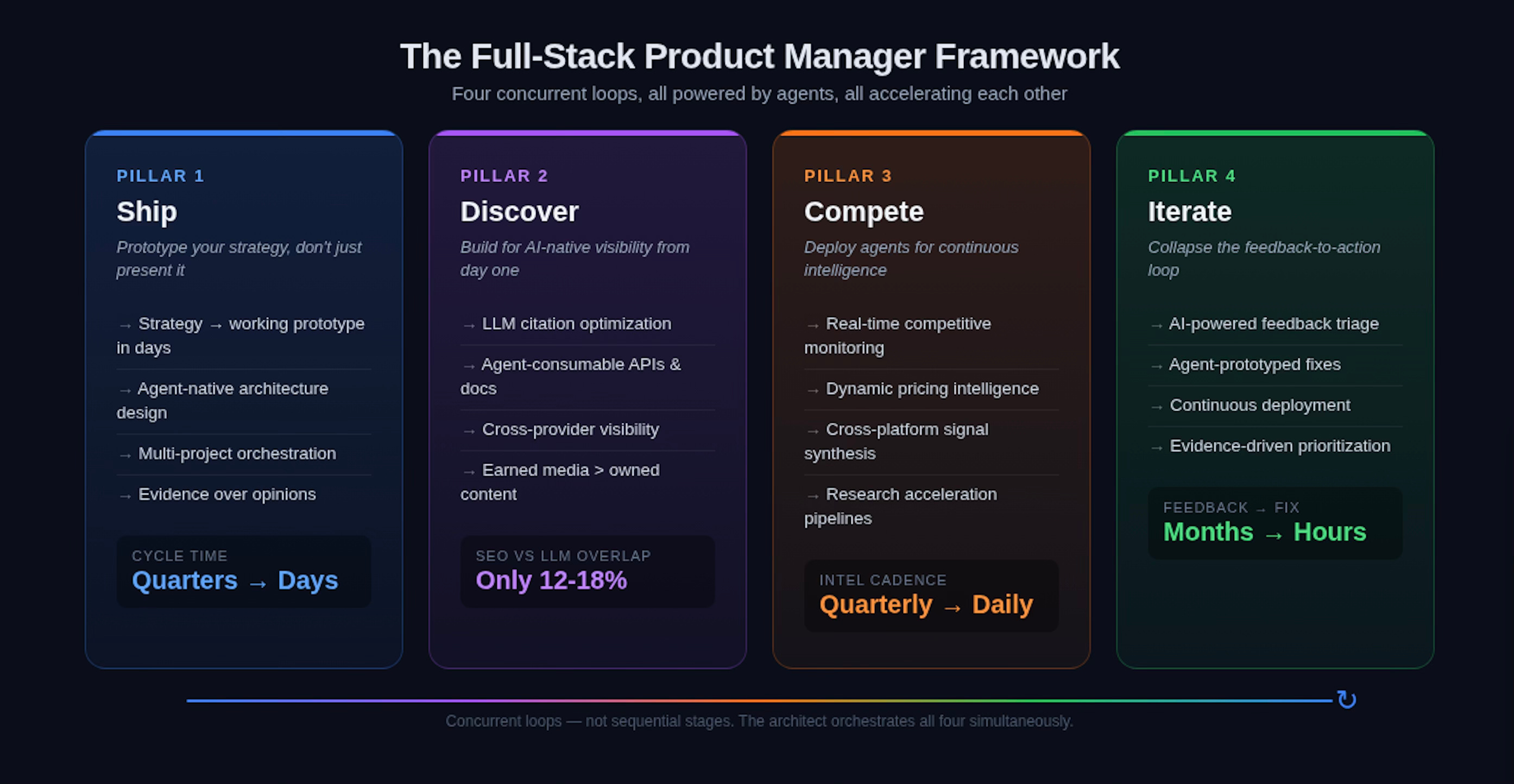
The framework has four pillars:
Ship: Prototype your strategy, don’t just present it
Discovery: Build for AI-native visibility from day one
Compete: Deploy agents for continuous competitive intelligence
Iterate: Collapse the feedback-to-action loop from sprints to hours
Each of these represents a fundamental departure from how product organizations have operated for the past two decades, and from the frameworks those organizations were built on.
Consider how the canonical PM playbooks transform under this model. Eric Ries’s Build-Measure-Learn loop doesn’t disappear. It accelerates from weeks to hours. When agents can prototype a feature in an afternoon and instrument it for real user data by evening, you’re not running one lean experiment per sprint. You’re running dozens per week. The constraint shifts from cycle time to judgment: which experiments are worth running?
Jobs to Be Done: Clayton Christensen’s framework for understanding what customers actually hire your product to accomplish evolves from periodic qualitative research to continuous signal detection. Instead of 10-20 customer interviews per quarter, agents can monitor thousands of support tickets, community conversations, and behavioral patterns to surface emerging jobs in real time. The human PM’s role shifts from “conduct the interviews” to “decide which discovered jobs matter strategically.”
And Teresa Torres’s Continuous Discovery: structured, frequent conversations with users to identify problems worth solving—transforms from a cadence (weekly interviews) into a continuous information flow. Agents conduct hundreds of conversations; humans synthesize patterns and decide which insights warrant exploration.
The frameworks aren’t obsolete. They’re unshackled from human bandwidth. The full-stack PM doesn’t abandon these tools — they run them at machine speed, reserving human judgment for the decisions that actually require it.
Pillar 1: Ship Your Strategy
Garry Tan, Y Combinator’s CEO, has been vocal about the progression people go through with “vibe coding,” from not using AI at all to increasingly sophisticated collaboration with AI agents. His own toolkit, gstack structures Claude Code workflows with specialized roles (CEO, Designer, Eng Manager, QA) to manage complex projects.
But here’s what most people miss: the progression doesn’t stop at “good at vibe coding.” Most practitioners plateau around he called Level 3 or 4: they can prompt effectively, they accept diffs without reading every line (the original Karpathy definition2), and they ship small projects faster than before. That’s table stakes now.
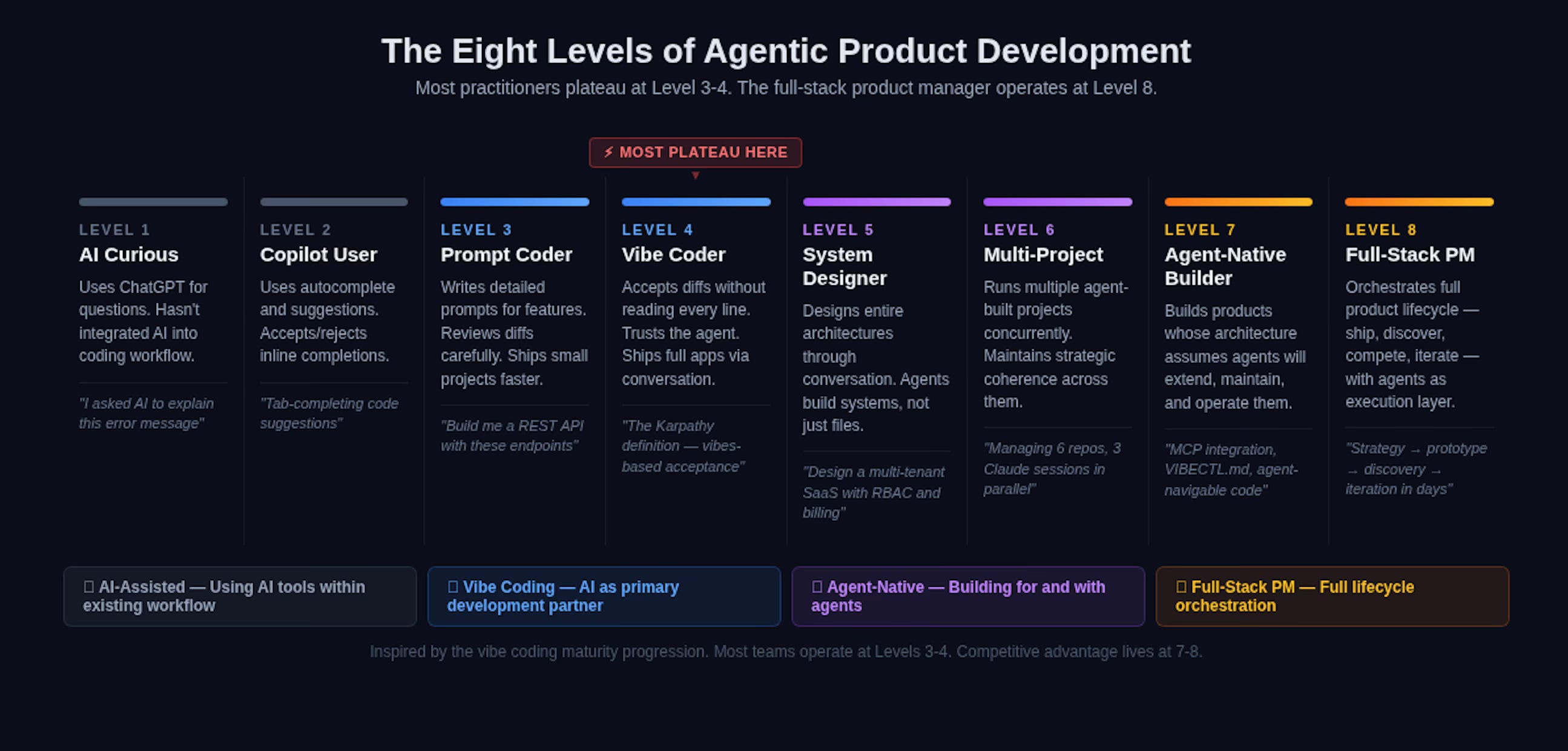
The levels beyond that are where the real transformation happens. Level 5 is directing agents across entire architectures: not just writing code, but designing systems through conversation. Level 6 is running multiple agent-built projects concurrently, maintaining strategic coherence across them. Level 7 is building agent-native infrastructure; products whose architecture assumes AI agents will extend, maintain, and operate them. And Level 8 is the full-stack PM: orchestrating the full product lifecycle, from competitive intelligence through shipping through discovery, with agents as the primary execution layer and human judgment as the strategic spine.
At this level, the person directing the agents isn’t just coding faster. They’re operating at the product level, coordinating multiple agent-built systems simultaneously, cycling between strategy and implementation fluidly, and maintaining coherence across a portfolio of rapid-fire projects.
This is where traditional tooling breaks down catastrophically. Jira doesn’t understand agentic workflows. Linear doesn’t know your agent’s context window is finite. GitHub Issues doesn’t grasp that your “engineering team” is you and three Claude sessions running in parallel. Traditional PM tools were built for human-to-human coordination patterns: sprint planning, standup notes, story points. None of that maps to a workflow where your primary constraint is context management across multiple AI sessions, and where “sprint velocity” is measured in shipped features per day rather than story points per two-week cycle.
The tooling gap between “vibe coding one project” and “orchestrating an agent-powered product organization” is enormous — and it’s a gap that reveals something important about where product leadership is headed.
I hit this wall myself when I was running six agent-built projects simultaneously. No project management tool understood the constraints: finite context windows, multi-agent coordination, the pace at which decisions needed to be made and tracked. So I built VibeCtl—a command-and-control system designed specifically for the agentic development workflow. It uses a VIBECTL.md file as a single source of truth that both humans and agents can read, integrates directly via MCP (Model Context Protocol) so agents never leave their coding environment, and tracks health, feedback, and deployment across projects that move at the speed of thought.
The point isn’t the specific tool. The point is the principle: if your strategy can’t become a working prototype in a weekend, you need to ask whether it’s actually a strategy or just a hope.
Consider what this looks like in practice. Chessmata (a multiplayer chess platform where humans and AI agents compete on equal footing) was built in a weekend using what I call “English-only programming.” The backend is Go with WebSocket multiplayer. The frontend is React with Three.js 3D rendering. It has Elo-based matchmaking, MCP integration for agent players, and a reference AI (Maia-2) that plays like a human at any skill level. Not a prototype. A production system.
Or take LastSaaS: a complete, production-ready SaaS boilerplate with multi-tenant architecture, Stripe billing, RBAC, OAuth, webhooks, API keys, product analytics, and 26 MCP admin tools. Built entirely through conversation with Claude Code by one person. It’s not notable because it exists — SaaS boilerplates have existed for years. It’s notable because the codebase was designed for AI-assisted extension: consistent patterns, clear naming conventions, agent-navigable structure. The product architecture itself assumes agents will continue building it.
The “Ship Your Strategy” principle isn’t about moving fast and breaking things. It’s about closing the gap between insight and evidence. When you can prototype a strategic hypothesis in days rather than months, you’re not just faster—you’re operating on a fundamentally different learning curve. You have real user data while your competitor is still getting stakeholder buy-in on a Figma mock.
The 10x PM is now the 100x PM. Not because the individual works harder, but because the loop between “I think this might work” and “let’s see if it actually works” has collapsed from a quarter to a weekend.
Pillar 2, Discover: Build for the AI-Native Web
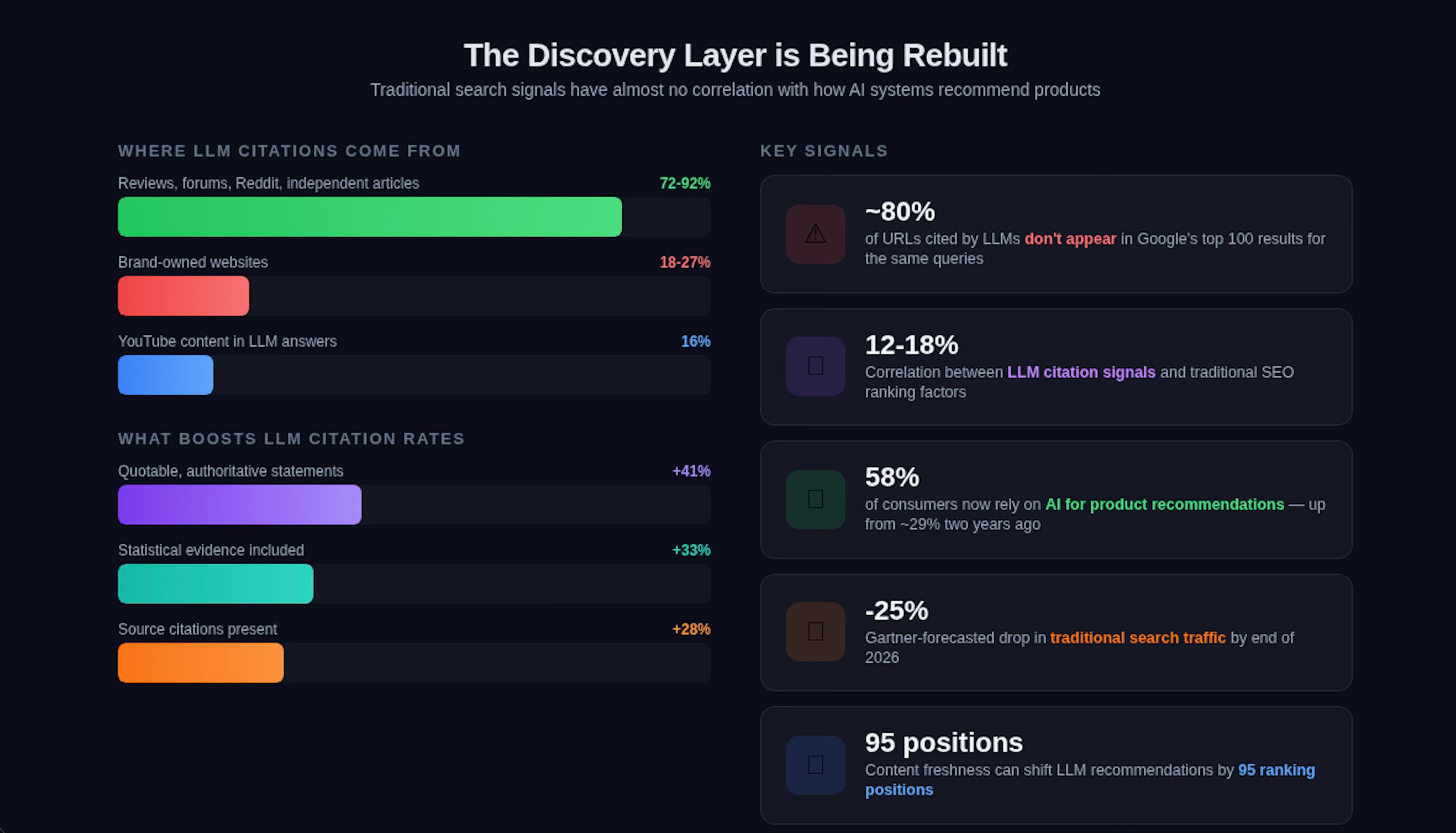
Here’s a statistic that should reframe how every product leader thinks about go-to-market: according to recent GEO research, roughly 80% of URLs cited by major LLMs don’t appear in Google’s top 100 results for the same queries.3
Read that again. The content that AI systems recommend to users has almost no correlation with traditional search rankings. LLM citation signals correlate only 12-18% with traditional SEO. And this matters enormously, because 58% of consumers now rely on AI for product recommendations—up from roughly 29% just two years ago.
Gartner forecasts a 25% drop in traditional search traffic by end of 2026. Google’s own growth has been visibly dampened by ChatGPT and other AI interfaces. Younger generations already treat Google as a backup, not a first stop. The entire discovery layer of the internet is being restructured—and most product organizations haven’t even started adapting.
I’ve spent significant time researching this shift, and the data is stark. What I’ve found—and documented in depth in my piece on LLM optimization and marketing in the age of AI discovery — is that AI-native discoverability requires a fundamentally different playbook:
Quotability dominates. Adding authoritative, quotable statements to your content increases LLM citation rates by 41%. AI systems are looking for definitive, citable claims—not keyword-optimized filler. Structure your product content as if every paragraph might be quoted by an AI recommending solutions to a user.
Earned media outweighs owned content. Between 72% and 92% of LLM citations come from reviews, forums, Reddit threads, and independent articles — not from brand-owned websites. Only 18-27% of citations come from your own site. This means your “content marketing strategy” needs to prioritize how others talk about you, not just what you say about yourself.
Freshness crushes authority. Content freshness can shift an LLM’s recommendations by 95 positions. The decades-old SEO wisdom that domain authority compounds over time is being disrupted by AI systems that heavily weight recency.
Cross-provider variation is extreme. Citation concentration varies between 28% and 67% across different AI systems, with content similarity scores between 0.11 and 0.58. What Claude recommends and what ChatGPT recommends are often wildly different. You can’t optimize for one model and assume coverage.
Video is critical. YouTube content appears in 16% of all LLM answers. If your product strategy doesn’t include a video authority component, you’re invisible to a significant slice of AI-driven discovery.
The implication for product leaders is profound: discoverability isn’t a marketing function anymore. It’s a product architecture decision. If your APIs aren’t structured for agentic consumption, if your documentation isn’t optimized for LLM parsing, if your content strategy doesn’t account for how AI systems select and cite sources—your product is structurally disadvantaged in the discovery layer.
I’ve built LLM Optimizer — an open-source tool that analyzes how AI systems perceive and recommend brands across Claude, ChatGPT, Gemini, and Grok — specifically because I realized there was no instrumentation for this new reality. It measures Answer Engine Optimization, Video Authority, Reddit Authority, Search Visibility, and direct LLM Knowledge Testing to produce a composite AI Visibility Score. Think of it as the “Google Search Console” equivalent for the AI-native web.
But the broader strategic point transcends any single tool: the full-stack PM treats AI discoverability as a core product metric, right alongside activation rates and retention curves. Because in a world where AI agents increasingly mediate how users find and evaluate software, being invisible to those agents is existential.
I explored this theme from the other direction when I built an agent that discovers other agents — a self-improving directory system where AI agents autonomously catalog tools, MCP servers, and workflows. The most striking finding: most of the internet is not designed for agentic consumption. Marketing pages optimized for human eyes resist programmatic parsing. Companies without agent-friendly documentation — clean JSON APIs, structured metadata, semantic markup — are invisible to the autonomous discovery mechanisms that will increasingly drive software adoption.
The product leaders who build for AI-native discovery now will have a compounding advantage. Those who wait will find themselves optimizing for a distribution channel — traditional search — that is structurally declining.
Pillar 3, Compete: Deploy Agents as Your Intelligence Network
Most competitive intelligence in product organizations is still artisanal. Someone on the team monitors competitors’ blogs. Maybe there’s a quarterly battlecard refresh. Pricing changes get noticed weeks after they happen, usually because a sales rep lost a deal.
This is absurd in 2026. We have access to autonomous reasoning systems that can monitor thousands of channels simultaneously, distinguish signal from noise, and synthesize findings into actionable intelligence in real time. Yet most product teams still treat competitive intelligence as a periodic human effort.
The full-stack PM deploys agents as a continuous intelligence network:
Competitive monitoring. Agents that track competitor product launches, pricing changes, positioning shifts, and hiring patterns across their websites, job boards, GitHub repos, social media, and community forums — and surface only the signals that warrant strategic attention. Not a dashboard you check weekly. A system that interrupts you when something matters.
Pricing intelligence. Agents that model competitive pricing dynamics and recommend positioning adjustments. The tools emerging in this space — platforms like Klue and Crayon — are evolving toward agentic architectures where the system doesn’t just collect data but reasons about strategic implications.
Market signal synthesis. Agents that aggregate customer feedback from support tickets, community forums, social media, and review sites — then triangulate patterns against competitive movements to identify emerging opportunities or threats. When a competitor’s users start complaining about the same issue on three different platforms simultaneously, your agent should know about it before their product team does.
Research acceleration. I built Paper Scout to automate academic research monitoring; it tracks arXiv, Semantic Scholar, and Hugging Face daily, scores papers against my interest profile using local embeddings, and surfaces findings through MCP tools in Claude. The principle applies broadly: any knowledge domain relevant to your product strategy can be monitored by agents that handle volume and speed, leaving human judgment for assessment and strategic interpretation.
The shift isn’t from “humans do competitive intel” to “agents do competitive intel.” It’s from episodic, reactive analysis to continuous, proactive intelligence — with humans focusing on the judgment calls that agents surface, rather than the data gathering that precedes them.
Here’s where this connects back to the broader thesis: the same agentic infrastructure that lets you ship faster also lets you see faster. When your competitive intelligence loop runs continuously rather than quarterly, you can respond to market shifts in days rather than months. Combined with the ability to prototype and ship in weekends, the entire strategic cycle compresses dramatically.
The competitive advantage doesn’t go to the company with the best strategy. It goes to the company that can cycle through the strategy-to-evidence loop fastest.
There’s a deeper pattern here worth naming. In my analysis of enshittification and the future of AI agents, I’ve argued that the current fragmentation of platforms—Slack, Discord, WhatsApp, each a silo designed to prevent interoperability—creates a structural opportunity for agents. Agents can float above fragmented platforms, orchestrating intelligence gathering across channels that were never designed to interoperate. Your competitive intelligence agent doesn’t care that your competitor’s community is on Discord while their support forum is on Zendesk and their hiring is on LinkedIn. It operates at the semantic layer, extracting signal from wherever it exists.
This is also why the full-stack PM’s competitive intelligence function naturally extends into positioning and pricing strategy. When your agents are continuously monitoring how competitors frame themselves, how their users respond, and how AI systems describe the competitive landscape, you have the raw material to dynamically adjust your own positioning — not in quarterly strategy reviews, but in real time.
Pillar 4, Iterate: Collapse the Feedback Loop
The conventional product feedback loop looks something like this: users report issues through support channels, which get triaged into a backlog, which gets prioritized in a sprint planning meeting, which leads to engineering work, which ships in the next release cycle. Best case, six weeks from feedback to fix. Typical case, three to six months.
In the agentic era, this is inexcusably slow.
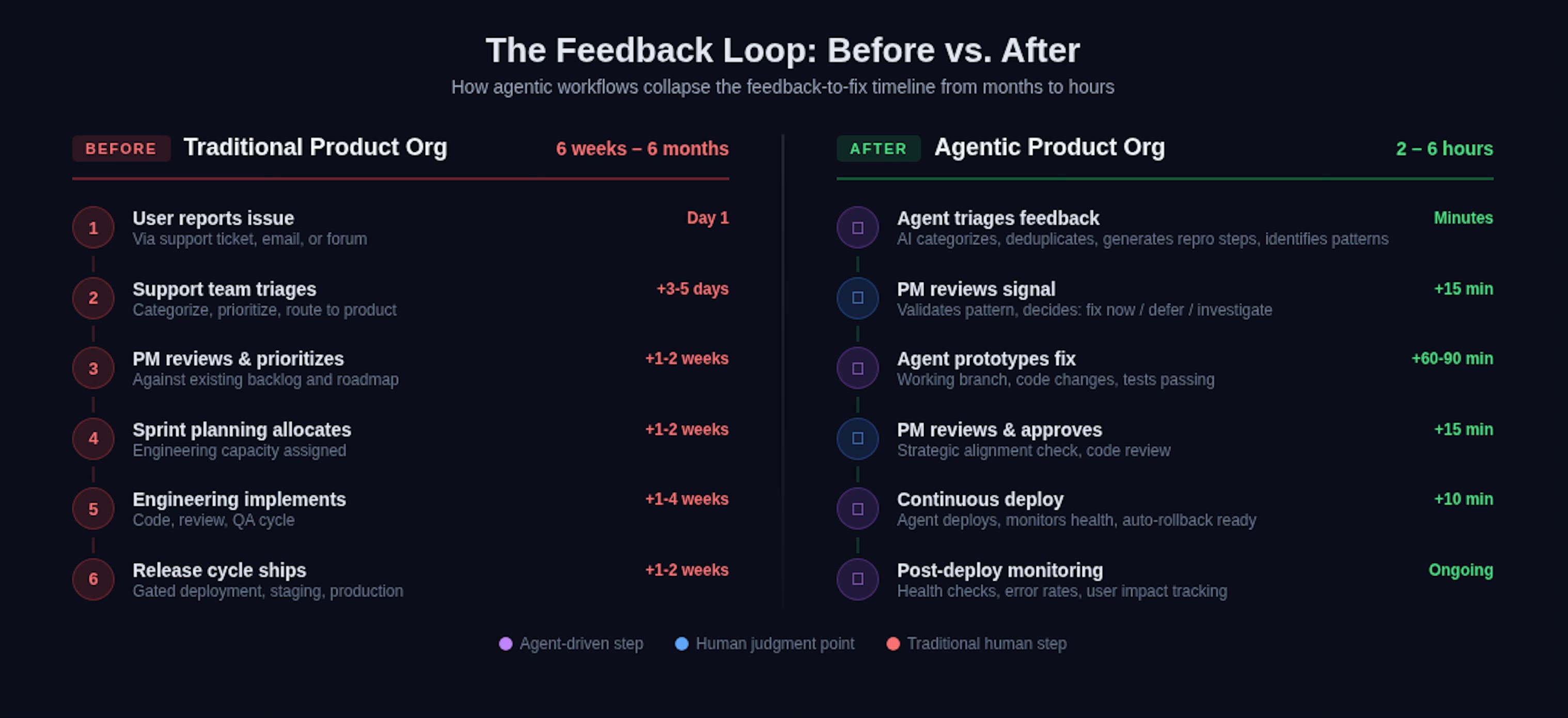
This pillar demands feedback systems where user inputs flow directly into the development loop with minimal human friction. Not by removing human judgment, but by automating everything around the judgment:
Automated feedback triage. User reports — from support tickets, community forums, in-app feedback widgets — are processed by AI that categorizes, deduplicates, identifies patterns, and converts raw user language into structured issues with severity assessments and reproduction steps. The human role shifts from “process the firehose” to “validate the filtered signal and decide on priority.”
Rapid prototyping of fixes. When a critical feedback pattern emerges, an agent can prototype the fix — not just write the code, but create a working branch, run tests, and present the human with a reviewable solution. The product lead’s job isn’t to spec the fix and wait for engineering. It’s to evaluate whether the fix aligns with the broader product direction and approve it.
Continuous deployment as default. When the feedback-to-fix loop runs in hours rather than sprints, gated release cycles become the bottleneck. The agentic product organization deploys continuously, with agents monitoring production health and rolling back automatically if issues emerge.
Evidence-driven prioritization. Instead of quarterly planning sessions where prioritization is driven by stakeholder opinions and HiPPO dynamics,4 the feedback loop generates continuous quantitative evidence about what users actually need — triangulated across support data, behavioral analytics, competitive intelligence, and market signals. The PM’s role isn’t to collect this data manually. It’s to build the agentic systems that synthesize it and surface the priorities that matter.
Qualitative feedback at scale. One of the most influential pieces in product management history is Rahul Vohra’s account of how Superhuman built an engine to find product-market fit. The quantitative piece was elegant: ask users “How would you feel if you could no longer use this product?”, track the percentage who say “very disappointed,” and aim for 40%. Superhuman went from 22% to 58% using this method. But the hard part was always the qualitative layer—understanding why users felt that way, segmenting by persona, mining the “somewhat disappointed” cohort for convertible users, and synthesizing open-ended responses into actionable product direction. That qualitative synthesis used to take weeks of manual coding and analysis. Today, an agent can process thousands of qualitative survey responses in minutes: clustering themes, identifying persona patterns, cross-referencing against behavioral data, and surfacing the exact friction points that separate “somewhat disappointed” from “very disappointed” users. The Superhuman methodology hasn’t changed—the 40% threshold, the focus on high-expectation customers, the 50/50 roadmap split between “double down on love” and “address barriers”—but the speed at which you can run the entire engine has collapsed from quarters to days.
Product-market fit is no longer something you measure periodically. It’s something you instrument continuously.
The compound effect of collapsing all four loops—shipping, discovery, competitive intelligence, and iteration—is that the entire product organization operates on a fundamentally different clock speed. Not “agile” in the two-week-sprint sense. Agile in the this-afternoon sense.
To make this concrete: the feedback triage system in VibeCtl uses Claude to automatically convert user reports into structured issues — categorized, severity-assessed, and linked to the relevant project context. A user submits a bug report in natural language; the agent parses it, checks it against known issues, generates reproduction steps, and presents it to me as a decision: fix now, defer, or investigate further. If I choose to fix, an agent can have a working branch with tests within the hour. That’s not a theoretical workflow. That’s Tuesday.
The old model—support team triages, PM prioritizes, engineering estimates, sprint planning allocates—was designed for a world where implementation was the bottleneck. When implementation takes hours instead of weeks, the bottleneck shifts to decision quality and speed. The full-stack PM optimizes for that bottleneck, not the old one.
The Governance Imperative
Speed without governance is recklessness. And this is where I part ways with much of the current discourse around agentic product development.
The data is sobering: AI co-authored code contains 1.7 times more major issues than human-written code and 2.74 times more security vulnerabilities.5 Sixty-three percent of developers report spending more time debugging AI-generated code than it would take to write it from scratch. And fewer than 10% of enterprises running production agents can govern them effectively.
The responsible builder doesn’t ignore these realities. They build governance into the system from the start:
Provenance and audit trails. Every agent action—every code commit, every competitive intelligence finding, every feedback triage decision—is logged with full chain of custody. Not for compliance theater, but because when you’re operating at agentic speed, the ability to understand why a decision was made and who (human or agent) made it becomes critical for debugging both code and strategy.
Constitutional guardrails. Hard constraints that agents cannot cross, regardless of what they optimize for. These aren’t just ethical boundaries (though those matter too). They’re product strategy boundaries: pricing floors the competitive intelligence agent can’t recommend below, user data the feedback triage agent can’t access without human approval, deployment environments the CI/CD agent can’t push to without review.
Human-in-the-loop architecture. The critical design decision is where agents handle volume and speed versus where humans retain judgment and approval. The art is knowing where those decision points are, and that knowledge comes from deep product experience, not from prompting techniques.
Recent research from Wharton makes the stakes of this design decision disturbingly concrete. Shaw and Nave’s “Thinking — Fast, Slow, and Artificial” extends Kahneman’s dual-process model by identifying a third cognitive system: System 3, the AI layer that increasingly mediates human decision-making.6 Their key finding is what they call cognitive surrender—the tendency to adopt AI outputs without critical scrutiny. Across three studies with 1,372 participants, they found that when AI provided correct guidance, accuracy jumped by 25 percentage points. But when AI was wrong, accuracy dropped by 15 points—and critically, participants’ confidence in their answers remained inflated regardless. People didn’t just follow bad AI advice. They believed they’d arrived at the answer independently.
The effect size (Cohen’s h = 0.81) is large enough to matter at the product level. And the finding that people with lower “need for cognition”—those who prefer intuitive over analytical thinking—surrender more readily has direct implications for how product teams interact with agentic tools. The full-stack PM’s governance architecture isn’t just about catching agent errors. It’s about designing workflows that structurally resist cognitive surrender — ensuring that human review points are genuine decision gates, not rubber stamps on AI recommendations.
The agent error compounding problem illustrates why this matters at scale: if you chain 20 steps, each 95% reliable, your end-to-end success rate is only 36%. Knowing which steps can be fully automated, which need human checkpoints, and how to structure the overall workflow so that errors are caught before they compound — that’s the governance dimension of the full-stack PM’s role. Shaw and Nave’s research suggests the compounding isn’t just technical — it’s cognitive. Each time a human “reviews” agent output without genuine scrutiny, the probability of catching downstream errors degrades further.
The Machine Societies Are Already Here (And They Change All Four Pillars)
One dimension of this transformation that gets insufficient attention — and that compounds across all four pillars — is that agents don’t just work for you. They increasingly interact with each other.
I’ve tracked this extensively in my research on the age of machine societies. There are now 17,000+ MCP servers enabling agent-to-agent communication. Platforms like Moltbook have hosted 770,000+ agents autonomously posting, voting, and coordinating. Google’s Werewolf Arena has revealed that different AI models have distinct strategic signatures — GPT-4’s verbosity becomes a tell, while Gemini’s casual style reads as more authentic in deception scenarios.
For product strategy, the implications are significant:
Agent-to-agent marketplaces are emerging. Your product doesn’t just need to be discoverable by humans. It needs to be consumable by other agents. MCP integration, clean API design, and structured metadata aren’t nice-to-haves — they’re the equivalent of having a website in 2005.
Network effects follow Reed’s Law. When agents can easily form subgroups and collaborate, value grows not as n (Metcalfe’s Law) but as 2^n (Reed’s Law).7 Products that facilitate agent-to-agent connections will generate exponentially more value than those designed purely for human users.
Security becomes a product feature. In a world of autonomous agent interaction, prompt injection attacks, malicious plugins, and coordinated agent manipulation are real threats. Products with robust agent governance will command premium positioning — security becomes a differentiator, not a cost center.
In my market map of the agentic economy, I identified seven layers — from physical infrastructure (silicon, energy) up through compute, knowledge substrate, foundation models, platforms, creation and orchestration tools, to the agent experience layer at the top. The full-stack PM needs to understand where their product sits in this stack, because the dynamics at each layer are radically different. At Layer 7, ASML’s $350 million EUV lithography machines are the only equipment on Earth capable of printing the chips agents run on. At Layer 6, Big Tech has committed over $700 billion in AI capex for 2026 alone. At Layer 2, MCP has crossed 10,000 active servers with 97 million monthly SDK downloads. And at Layer 1, 58% of consumers now rely on AI for product recommendations—with 93% of those sessions ending without a single click to a website. The products that invest in being MCP-native and agent-consumable today are building the equivalent of early web standards compliance: boring infrastructure work that compounds into decisive strategic advantage. Every new tool connected to the network makes every agent more capable, and every new agent makes every tool more valuable—classic Reed’s Law dynamics playing out in real time.
What This Means for You
If you’re a startup founder: the window for building AI-native is right now. Not “AI-enhanced” — truly native, where agents are first-class participants in your product architecture from day one. The SaaS companies losing market cap are the ones who treated AI as a feature. The ones gaining ground are the ones who treated it as an architecture.

If you’re a product leader at scale: the organizational shift is harder than the technical one. You need product people who can prototype, not just spec. You need feedback systems that run in hours, not sprints. You need competitive intelligence that’s continuous, not quarterly. And you need to accept that the PM role as you’ve known it —the coordinator, the spec writer, the stakeholder aligner—is being absorbed into something more integrated and more powerful.
If you’re a technical PM or builder—or a software engineer with product instincts: you’re already closer to this than you think. The skills that matter in the agentic era aren’t new. They’re product judgment—knowing what to build, for whom, and why—combined with the ability to actually build it, rapidly, using agents as force multipliers. The full-stack PM doesn’t replace product thinking with engineering. They unify them. And that convergence runs both directions: PMs who can prototype are leveling up, and engineers who understand users and markets are becoming the PMs. The 25-40% salary premium that agentic PM roles command over generalist PMs right now isn’t about prompt engineering skill—it’s about this integration of strategic judgment and execution capability.
The emergence of formal “Agentic Product Manager” roles at Microsoft, Citi, and IFS signals that the market recognizes this shift. But the role title is less important than the capability: can you go from strategic hypothesis to shipped evidence in days? Can you instrument your product for AI-native discovery? Can you deploy agents that make your competitive intelligence continuous rather than episodic? Can you build feedback loops that run at the speed of your agents, not the speed of your sprint calendar?
The four pillars—Ship, Discover, Compete, Iterate—aren’t sequential. They’re concurrent loops, all running simultaneously, all powered by agents, all accelerating each other. The product leader who can orchestrate all four is operating at a velocity that traditional product organizations simply cannot match.
The Bottleneck Has Moved
For decades, the bottleneck in product development was engineering capacity. Could we build it? How many engineers do we need? What’s the timeline?
That bottleneck has moved. Inference costs have fallen 92%—from $30 to under $2.50 per million tokens. Claude Opus 4.6 exceeds human experts on PhD-level reasoning. Autonomous task horizons are doubling every 123 days. Four percent of GitHub commits are already made by Claude Code, projected to exceed 20% by year-end. Eighty percent of databases on Neon are created by AI agents.
The new bottleneck is imagination. It’s knowing what to build and why — and having the strategic judgment to navigate a world where shipping is cheap but attention is expensive, where agents can build anything but governance determines what they should build, and where the discovery layer that connects products to users is being rebuilt in real time.
That’s the job of the full-stack product manager. Not a new title—an expanded one. The same strategic judgment that always defined great PMs, now extended across the full product lifecycle by agents that make one person’s vision operationally viable at a scale that used to require an entire organization.
The strategy deck era is over. Ship your strategy. Let the evidence do the talking.
The tools are here. The cost curves have crossed. The only question left is whether you’ll be the one shipping—or the one watching your roadmap get built by someone who moved faster.
Further Reading
My previous work on the frameworks behind this piece:
Market Map of the Agentic Economy — the seven-layer value chain from silicon to agents, with competitive positioning analysis of every major player
LLM Optimizer: Marketing in the Age of AI Discovery — deep dive into how LLM citation signals diverge from traditional SEO, and what product teams need to do about it
Software’s Creator Era Has Arrived — the thesis that language models are compilers for natural language, and what that means for who can build software
How Superhuman Built an Engine to Find Product-Market Fit (First Round Review) — the foundational product-market fit methodology referenced in Pillar 4, and still the best framework for systematic PMF measurement
Practical Guide to Controlled Experiments on the Web: Listen to Your Customers not to the HiPPO (Kohavi et al., KDD 2007) — the paper that formalized the case against gut-feel product decisions; now assigned reading at Stanford
GEO: Generative Engine Optimization (Aggarwal et al., 2024) — the academic research behind the discovery shift, showing how LLM citation signals diverge from traditional search
The Spotify Model: Why It Failed and What AI Changes — how autonomous squads evolve when AI agents handle coordination complexity
Thinking — Fast, Slow, and Artificial: A Tri-System Theory of Cognition (Shaw & Nave, Wharton 2025) — the research behind “cognitive surrender” and why human-in-the-loop governance requires structural design, not just good intentions
Why LinkedIn Is Replacing PMs with AI-Powered “Full-Stack Builders” (Lenny Rachitsky, Dec 2025), on how LinkedIn CPO Tomer Cohen is scrapping the APM program, creating the Associate Product Builder role, and building a Full Stack Builder career ladder
If you’re navigating this transition — whether you’re rethinking your product org, building AI-native for the first time, or figuring out how agents fit into your competitive strategy — I’d love to hear what’s working and what isn’t. The best conversations I’ve had on this have been with people who are building, not just theorizing. Reach out, reply here, or find me on LinkedIn or X.
Footnotes
When Grace Hopper built the first compiler in 1952, she later recalled that “nobody believed that,” because the prevailing wisdom was that computers could only do arithmetic, not write programs. Her colleagues told her a computer couldn’t write code because “it doesn’t understand English.” Seventy-four years later, we’re having the same argument in reverse — except now the computer does understand English, and the resistance comes from people who insist that understanding English isn’t the same as understanding software. They’re right, technically. But Hopper was right, practically. The compiler won. ↩
Andrej Karpathy coined “vibe coding” in a February 2025 tweet describing a new mode of programming where “you fully give in to the vibes, embrace exponentials, and forget that the code even exists.” He described accepting diffs without reviewing them, running code to see if it “vibes right,” and relying on the LLM to fix errors when something breaks. The term went viral because it named something developers were already doing but felt mildly guilty about. ↩
Based on findings from Aggarwal et al., “GEO: Generative Engine Optimization” (2024), combined with subsequent cross-provider citation analyses by BrightEdge (2025) and the NanoKnow benchmark for measuring factual accuracy across LLM providers. The 80% figure represents aggregate findings across ChatGPT, Perplexity, Gemini, and Claude when tested against equivalent Google Search queries. ↩
HiPPO, the “Highest Paid Person’s Opinion,” was coined by Dylan Lewis at Intuit around 2006 and popularized by Ronny Kohavi’s Experimentation Platform team at Microsoft, who distributed thousands of toy hippos across the company as a cultural intervention against gut-feel product decisions. (Kohavi’s 2007 KDD paper, “Practical Guide to Controlled Experiments on the Web: Listen to Your Customers not to the HiPPO,” is now assigned reading at Stanford and the University of Washington.) The data on HiPPO’s costs is striking: an Oracle study of 14,000 employees across 17 countries found that 74% believe their organizations routinely put the highest-paid person’s opinion ahead of data, while Kahneman’s research shows that simple formulas and algorithms beat expert intuition at least 60% of the time across diverse domains. McKinsey found data-driven companies are 23x more likely to acquire customers. But the picture isn’t one-sided: Gary Klein’s Sources of Power research demonstrates that expert intuition genuinely outperforms data in domains with immediate feedback, regularity, and time pressure—firefighters, surgeons, chess masters. The catch for product orgs is that most product decisions fail all three of Klein’s conditions: feedback is delayed, markets are irregular, and there’s rarely genuine time pressure (just manufactured urgency). The HiPPO isn’t always wrong, but the conditions under which they’re reliably right are much narrower than most executives believe. ↩
GitClear’s 2025 code quality analysis of 211 million lines of changed code, corroborated by Snyk’s AI code security audit. The security vulnerability figure (2.74x) specifically measures CWE-classified vulnerabilities in code where AI tools were used versus code written entirely by humans. Interestingly, the gap narrows significantly when the developer has 10+ years of experience — suggesting the issue isn’t AI-generated code per se, but inexperienced developers using AI as a substitute for understanding rather than a supplement to it. ↩
Shaw, A. & Nave, G. (2025). “Thinking — Fast, Slow, and Artificial: A Tri-System Theory of Cognition.” Working paper, The Wharton School, University of Pennsylvania. The paper proposes extending Kahneman’s System 1/System 2 framework to include System 3 — artificial cognition mediated by AI. Their three studies (N=1,372) found that AI influence on decision-making was asymmetric: correct AI guidance improved accuracy dramatically, but incorrect guidance degraded it — while subjective confidence remained elevated in both cases. The practical implication for product teams is unsettling: the people most likely to rubber-stamp agent outputs are the ones who feel most confident they’re exercising independent judgment. ↩
David P. Reed proposed his law in 1999, arguing that the value of group-forming networks scales exponentially — but for decades it was considered mostly theoretical, since few networks actually enabled fluid subgroup formation. Social media partially validated it (Facebook Groups, Discord servers), but agents may be the first context where Reed’s Law fully applies: agents can form, dissolve, and reform working groups in seconds, with zero coordination overhead. If Reed was right, the most valuable AI products won’t be the smartest agents — they’ll be the ones that make it easiest for agents to find and work with each other. ↩